بخشبندی تصوير بر مبنای طبقهبندی

در این مطلب قصد داریم تا بخشبندي تصوير بر مبناي طبقهبندي را جهت پردازش تصویر به شما معرفی کنیم، لطفا با ما همراه باشید.
مقدمه
طبقهبندي در واقع ارزشيابي ويژگيهاي مجموعهاي از دادهها و سپس اختصاص دادن آنها به مجموعهاي از گروههاي از پيش تعريف شدهاست. اين متداولترين قابليت داده کاوي ميباشد. داده کاوي را ميتوان با استفاده از دادههاي تاريخي براي توليد يک مدل يا نمايي از يک گروه براساس ويژگيهاي دادهها به کار برد. سپس ميتوان از اين مدل تعريف شده براي طبقهبندي مجموعه دادههاي جديد استفاده کرد. همچنين ميتوان با تعييننمايي که با آن سازگار است براي پيشبينيهاي آتي از آن بهره گرفت.
طبقهبندی
در واقع سيستمهايي که براساس طبقهبندي داده کاوي ميکنند، دو مجموعه ورودي دارند: يک مجموعه آموزشي که در آن دادههايي که به طور پيش فرض در دستههاي مختلفي قرار دارند، همراه با ساختار دستهبندي خود وارد سيستم ميشوند و سيستم براساس آنها به خود آموزش ميدهد يا به عبارتي پارامترهاي دستهبندي را براي خود مهيا ميکند. دسته ديگر از وروديهايي هستند که پس از مرحله آموزش و براي تعيين دسته وارد سيستم ميشوند . تکنيکهاي داده کاوي که براي دستهبندي به کار ميآيند عموماً شامل تکنيکهاي شبکه عصبي و درخت تصميمگيري هستند. هدف طبقهبندي دادهها، سازماندهي و تخصيص دادهها به کلاسهاي مجزا ميباشد. در اين فرايند براساس دادههاي توزيع شده، مدل اوليهاي ايجاد ميگردد. سپس اين مدل براي طبقهبندي دادههاي جديد مورد استفاده قرار ميگيرد، به اين ترتيب با بکارگيري مدل بدست امده، تعلق دادههاي جديد به کلاس قابل پيشگويي ميباشد. طبقهبندي در مورد مقادير گسسته و پيشگويي آنها به کار ميرود.هدف پيشگويي، پيش بيني و دريافت مقدار يک خصيصه براساس خصيصههاي ديگر ميباشد. براساس دادههاي توزيعي، در ابتدا يک مدل ايجاد ميگردد، سپس از اين مدل در پيشگويي مقادير ناشناخته استفاده ميشود. در داده کاوي، طبقهبندي، به پيشگويي مقادير گسسته و پيشگويي به تخمين مقادير پيوسته اتلاق ميشود. در فرايند طبقهبندي، اشيا موجود به کلاسهاي مجزا با مشخصههاي تفکيک شده (ظروف جداگانه) طبقهبندي و به صورت يک مدل معرفي ميگردند. سپس با در نظر گرفتن ويژگيهاي هر طبقه، شي جديد به آنها تخصيص يافته، برچسب و نوع آن پيشگويي ميگردد.در طبقهبندي، مدل ايجاد شده بر پايهي يکسري دادههاي آموزشي، (اشيا دادههايي که بر چسب کلاس آنها مشخص و شناخته شدهاست) حاصل ميآيد. مدل بدست آمده در اشکال گوناگون مانند قوانين طبقه بندي (If-Then)، درختهاي تصميم، فرمولهاي رياضي و شبکههاي عصبي قابل نمايش ميباشد. از طبقهبندي ميتوان براي پيشگويي کلاس اشيا دادهها استفاده کرد. در برخي موارد نيز افراد ترجيح ميدهند مقدار يک خصيصه و نه کلاس آن را پيشگويي نمايند که به يافتن مقدار يک خصيصه، پيشگويي اتلاق ميگردد. در هر حال پيشگويي، تخمين مقدار و بر چسب کلاس را با هم در بر ميگيرد. طبقهبندي و پيشگويي با استفاده از تحليل ارتباط، خصيصههايي را که فرايند مورد نظر، بي تاثير و قابل حذف ميباشند، شناسايي ميکنند.
طبقهبندی دادهها يک فرآيند دو مرحله ای است: 1-يادگيري 2–طبقهبندي
1-در مرحله اول يک مدل ساخته ميشود که مجموعهاي از کلاسهاي دادهاي يا مفاهيم را مشخص ميکند. اين مرحله را مرحله يادگيري گوييم که در ان يک الگوريتم طبقهبندي يک مدل را با تحليل يک مجموعهي آموزشي که مجموعهاي از تاپلهاي پايگاه دادهاست ميسازد و بر چسب کلاسهاي مربوط به اين تاپلها را مشخص ميکند. يک تاپل X با يک بردار صفت (x1،x2،…،xn)-X نمايش داده ميشود. فرض ميشود که هر تاپل به يک کلاس از پيش تعريف شده متعلق است و کلاس با يک صفت که به آن صفت بر چسب کلاس ميگوييم مشخص ميشود. مجموعه آموزشي به صورت تصادفي از پايگاه انتخاب ميشود. از آنجايي که برچسب هر تاپل آموزشي در اين مرحله مشخص است، اين مرحله يادگيري نظارت شده ناميده ميشود. 2- در مرحله دوم، از مدل ساختهشده براي طبقهبندي استفاده ميشود. يادگيري از طريق يک تابع (X)fy انجام ميشود که ميتواند برچسب کلاس هر تاپل X از پايگاه را پيشبيني کند. اين تابع به صورت قواعد طبقهبندي، درختهاي تصميمگيري يا فرمولهاي رياضي است. شکل زیر نشان ميدهد که چگونه يک تابع طبقهبندي ساخته شده و سپس دادههاي جديد بوسيله آن طبقهبندي ميشوند.
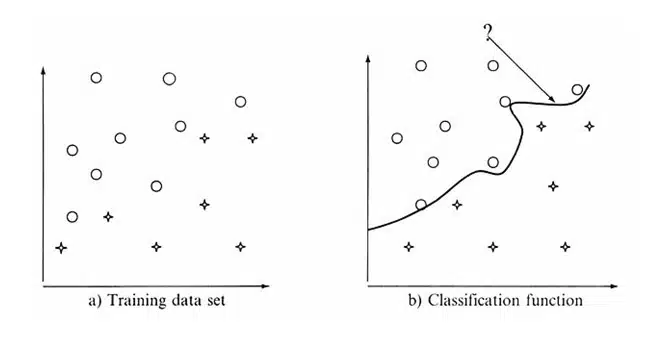
در ابتدا ميزان دقت مدل يا کلاسهبند تخمين زده ميشود. اين تاپلها تصادفي انتخاب شده و مستقل از تاپلهاي مجموعه آموزشي هستند. ميزان دقت در پيشگويي يک مدل روي مجموعه تست دادهشده برابر است با درصد تاپلهايي از تاپلهاي مجموعه تست که توسط مدل، درست طبقهبندي شدهاند. برچسب کلاس هر تاپل مجموعه تست، با برچسب کلاس پيشگويي شده براي آن تاپل توسط مدل يادگيري مقايسه ميشود اگر ميزان دقت مدل قابل قبول واقع شود، انگاه اين مدل ميتواند براي طبقهبندي تاپلهاي جديد با بر چسب کلاس نامعلوم استفاده شود. (در اصطلاحات يادگيري ماشين به اين نوع تاپلها يا دادهها unknown or previously unseen data گفته ميشود).
انواع روشهای طبقهبندی
- استنتاج بر اساس درخت تصميم
- طبقهبندي بيز
- شبکههاي عصبی
- نزديکترين همسايهها
- استنتاج مبتني بر مورد
- الگوريتمهاي ژنتيک
- مجموعههای فازی
ارزيابی روشهای طبقهبندی
ارزيابي روشهاي طبقهبندي با معيارهاي زير انجام ميپذيرد:
ميزان دقت
Classifer accuracy: ميزان قابليت و توانايي يک مدل در پيشگويي صحيح بر چسب يک کلاس.
Predictor accuracy: ميزان قابليت و توانايي يک مدل در حدس مقدار صفتهاي پيشگويي شده.
- سرعت و توسعه پذيري از نظر زماني که براي ايجاد يک مدل و زمان استفاده از آن مدل لازم ميباشد . اين زمان شامل مدت زمان ساخت مدل (زمانيادگيري) و مدت زمان استفاده از مدل (زمان طبقه بندي/پيشگويي) ميباشد.
- قوي بودن معيار مهمي است که ميزان توانايي يک مدل را دربرخورد با نويز و مقادير حذف شده تعيين ميکند.
- توسعهپذيري معيار ديگري است که از نقطه نظر ميزان کارايي در بانکهاي اطلاعات بزرگ و نه دادههاي مقيم در حافظه مورد بررسي قرار ميگيرد.
- قابل تفسير بودن يعني ميزان و سطح درک ايجاد شده توسط مدل از ديگر مواردي است که ميبايست در بررسي روشهاي طبقهبندي در نظر گرفت.
- ساير روشها از جمله شکل قوانين و نحوه نمايش انها از جمله سايز درخت تصميم و فشردگي و پيوستگي.
بررسی انواع روشهای طبقهبندی
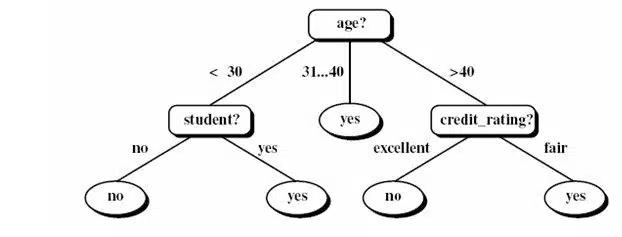
درخت تصميم
درخت تصميم يکي از ابزارهاي متداول براي دستهبندي و پيشبيني است. توليد يک درخت تصميم روش کارآمدي براي ايجاد رده، بندها يا طبقهبندي کنندهها بر روي دادهها است. اين درخت با بکارگيري يک استراتژي بالا به پايين به ايجاد آزمون بر روي هر گره ميپردازد. با توجه به ساختار بالا به پايين درخت تصميم اولين آزمون در گره ريشه که بالاترين گره در درخت است اتفاق ميافتد به اين صورت که يک رکورد جديد که برچسب کلاس آن نامشخص است در گره ريشه وارد ميشود و در اين گره يک آزمون صورت ميگيرد تا معلوم شود که اين رکورد به کدام يک از گرههاي فرزند تعلق دارد. اين فرايند آنقدر ادامه پيدا ميکند تا رکورد جديد به گرهي برگ برسد. هر گرهي برگ در درخت تصميم معرف يک برچسب کلاس يا يک دستهي مشخص ميباشد. بنابراين تمام رکوردهايي که به يک برگ از درخت ميرسند در يک دسته قرار ميگيرند. نمونهاي از درخت تصميم در شکل زیر مشاهده ميشود:
بيزين
الگوريتمهاي يادگيري بيزي به طور صريح بر روي احتمالات فرضهاي مختلف کار ميکنند. کلاسهبندهاي بيزي کلاسهبندهاي آماري هستند. آنها اعضاي کلاس را به صورت احتمالي پيشگويي ميکنند. مثلاً ميزان احتمال اينکه يک نمونه داده شده متعلق به يک کلاس خاص باشد. طبقهبندي بيزي بر مبناي تئوري بيز ميباشد. مقايسه الگوريتمهاي طبقهبندي نشان داده است که يک کلاسهبند بيزي ساده از نظر کارايي با کلاسه بندهاي درخت تصميم و شبکههاي عصبي قابل رقابت است و در برخي موارد بهتر از انها عمل ميکند. همچنین کلاسهبندهاي بيزي ميزان دقت و سرعت بالايي را هنگامي که در ديتابيسهاي بزرگ به کار برده ميشوند، ارائه ميدهند. Naïve Bayesian classifier فرض ميکند که تاثير يک مقدار صفت روي يک کلاس دادهشده، مستقل از مقادير ديگر صفتها ميباشد. به اين فرض استقلال شرطي کلاس گفتهميشود. اين فرض محاسبات را سادهتر ميکند و به همين دليل است که به اين روش naïve گفته ميشود. Bayesian belief network ها نيز که براي طبقهبندي استفاده ميشوند، مدلهاي گرافيکي هستند که بر خلاف naïve Baysian classifier ها وابستگي ميان زير مجموعهاي از صفتها را نمايش ميدهند.
روش طبقهبندي نزديکترين K- همسايه
هنگام تلاش براي حل مسائل جديد، افراد معمولاً به راهحلهاي مسائل مشابه که قبلاً حل شدهاند مراجعه ميکنند. k- نزديکترين همسايه (k-NN) يک تکنيک طبقهبندي است که از نسخهاي از اين متد استفاده ميکند. در اين روش تصميمگيري اينکه يک نمونه جديد در کدام کلاس قرار گيرد با بررسي تعدادي (k) از شبيهترين نمونهها يا همسايهها انجام ميشود. در بين اين k نمونه، تعداد نمونه ها براي هر کلاس شمرده ميشوند، و نمونه جديد به کلاسي که تعداد بيشتري از همسايهها به آن تعلق دارند نسبت داده ميشود. شکل زیر محدوده همسايگي نمونه N را نشان ميدهد. در اين محدوده، بيشتر همسايهها در کلاس X قرار گرفتهاند.
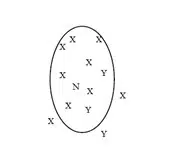
اولين کار براي استفاده از k-NN يافتن معياري براي شباهت يا فاصله بين صفات در دادهها و محاسبه آن است. در حالي که اين عمل براي دادههاي عددي آسان است، متغيرهاي دستهاي نياز به برخورد خاصي دارند. هنگامي که فاصله بين نمونههاي مختلف را توانستيم اندازه گيريم، ميتوانيم مجموعه نمونههايي که قبلاً طبقهبندي شدهاند را به عنوان پايه دستهبندي نمونههاي جديد استفاده کنيم. فهم مدلهاي K-NN هنگامي که تعداد متغيرهاي پيشبيني کننده کم است بسيار ساده است. آنها همچنين براي ساخت مدلهايي مانند متن که شامل انواع داده غير استاندارد هستند، بسيار مفيدند. تنها نياز براي انواع داده جديد وجود يک معيار مناسب شباهت است.
روش طبقهبندی شبکههای عصبی
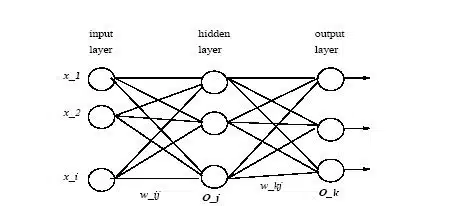
شبکه عصبي بوسيله الگوريتم پس انتشار خطا آموزش داده ميشود. اين شبکه از يک لايه ورودي، يک لايه خروجي و يک يا چند لايه نهان تشکيل شده است. هر گره در لايه ورودي معادل يکي از صفتهاي نمونه ورودي ميباشد و گرههاي لايه خروجي نشان دهنده کلاسها هستند. هريال بين گرههاي اين لايهها داراي يک وزن ميباشد که با يک مقدار تصادفي مقداردهي اوليه ميشود (به عنوان مثال رنجي بين 1.0- تا 1.0 يا 0.5- تا 0.5). در طول مرحله يادگيري، شبکه با تنظيم اين وزنها با استفاده از يک تابع آموزش و نمونه دادههاي آموزشي، عمل يادگيري را انجام ميدهد. الگوريتم طبقهبندي شبکه عصبي پرسپترون چند لايه (MLP)، اساس شبکههاي عصبي جلو برنده ميباشد. نمونهاي از اين شبکه دو لايهاي در شکل زیر مشاهده ميشود. جلو برنده، به اين معني است که مقدار پارامتر خروجي براساس پارامترهاي ورودي و يک سري وزنهاي اوليه تعيين ميگردد. مقادير ورودي با هم ترکيب شده و در لايههاي نهان استفاده ميشوند و مقادير اين لايههاي نهان نيز براي محاسبه مقادير خروجي ترکيب ميشوند.
روش طبقهبندی ماشين بردار پشتيبان
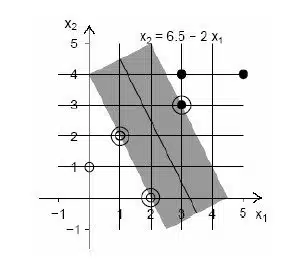
ماشين بردار پشتيبان (SVM) يکي از روشهاي يادگيري ماشين است که از تئوري يادگيري آماري سرچشمه ميگيرد و از آن براي طبقهبندي و رگرسيون استفاده ميکنند. اين روش از جمله روشهاي نسبتاً جديدي است که در سالهاي اخير کارايي خوبي براي طبقهبندي نسبت به روشهاي قديميتر از جمله شبکههاي عصبي پرسپترون نشان داده است. مبناي کاري طبقه بندي SVM، طبقه بندي خطي دادهها است. در تقسيم خطي دادهها سعي ميشود خطي انتخاب شود که حاشيه اطمينان بيشتري داشته باشد. براي يک مسئله طبقه بندي دو کلاسه، هدف جداسازي دو کلاس بوسيله يک تابع است که از نمونههاي آموزشي بدست ميآيد. شکل زیر يک مثال از يک مجموعه دادهي دو بعدي (دو کلاسه) را نشان ميدهد که کلاسهاي سياه رنگ و سفيد رنگ توسط خط x 2=6.5 – 2x 1 از هم جدا شدهاند. رنگ تيره در اطراف اين خط، ماکزيمم حاشيهان خط را نشان ميدهد.
شرکت نوین ایلیا صنعت از جمله شرکتهایی است که با دارا بودن نمایندگی رسمی برندهای فوقالعاده معتبری چون باسلر و سنسوپارت، نقش مهمی در زمینه طراحی و تولید سنسور پردازش تصویر و بهینهسازی فناوریهای مربوط به آن در ایران ایفا میکند. این شرکت با واردات قطعات و تجهیزات مطمئن و اورجینال به کشور، خدمات خود را به طرزی شایسته و با ضمانت معتبر به مشتریان خود ارائه مینماید. در حال حاضر شرکت نوین ایلیا صنعت در زمینه واردات فناوری پردازش تصویر، طراحی، پیادهسازی، نصب و راه اندازی سنسورها و ابزارها و دستگاههای لازم در این خصوص، به صورتی بی رقیب، پیشتاز میدان میباشد. در صورت نیاز به مشاوره در مورد این فناوری و یا هرگونه سوال درباره سنسور پردازش تصویر، ماشینهای بینایی، دوربینهای صنعتی و هوشمند کافی است با ما تماس بگیرید.





