بخشبندی تصویر بر مبنای طبقهبندی

در این مطلب قصد داریم تا بخشبندي تصوير بر مبناي طبقهبندي را جهت پردازش تصویر به شما معرفی کنیم، لطفا با ما همراه باشید.
مقدمه
طبقهبندی در واقع ارزشیابی ویژگیهای مجموعهای از دادهها و سپس اختصاص دادن آنها به مجموعهای از گروههای از پیش تعریف شدهاست. این متداولترین قابلیت داده کاوی میباشد. داده کاوی را میتوان با استفاده از دادههای تاریخی برای تولید یک مدل یا نمایی از یک گروه براساس ویژگیهای دادهها به کار برد. سپس میتوان از این مدل تعریف شده برای طبقهبندی مجموعه دادههای جدید استفاده کرد. همچنین میتوان با تعییننمایی که با آن سازگار است برای پیشبینیهای آتی از آن بهره گرفت.
طبقهبندی
در واقع سیستمهایی که براساس طبقهبندی داده کاوی میکنند، دو مجموعه ورودی دارند: یک مجموعه آموزشی که در آن دادههایی که به طور پیش فرض در دستههای مختلفی قرار دارند، همراه با ساختار دستهبندی خود وارد سیستم میشوند و سیستم براساس آنها به خود آموزش میدهد یا به عبارتی پارامترهای دستهبندی را برای خود مهیا میکند. دسته دیگر از ورودیهایی هستند که پس از مرحله آموزش و برای تعیین دسته وارد سیستم میشوند . تکنیکهای داده کاوی که برای دستهبندی به کار میآیند عموماً شامل تکنیکهای شبکه عصبی و درخت تصمیمگیری هستند. هدف طبقهبندی دادهها، سازماندهی و تخصیص دادهها به کلاسهای مجزا میباشد. در این فرایند براساس دادههای توزیع شده، مدل اولیهای ایجاد میگردد. سپس این مدل برای طبقهبندی دادههای جدید مورد استفاده قرار میگیرد، به این ترتیب با بکارگیری مدل بدست امده، تعلق دادههای جدید به کلاس قابل پیشگویی میباشد. طبقهبندی در مورد مقادیر گسسته و پیشگویی آنها به کار میرود.هدف پیشگویی، پیش بینی و دریافت مقدار یک خصیصه براساس خصیصههای دیگر میباشد. براساس دادههای توزیعی، در ابتدا یک مدل ایجاد میگردد، سپس از این مدل در پیشگویی مقادیر ناشناخته استفاده میشود. در داده کاوی، طبقهبندی، به پیشگویی مقادیر گسسته و پیشگویی به تخمین مقادیر پیوسته اتلاق میشود. در فرایند طبقهبندی، اشیا موجود به کلاسهای مجزا با مشخصههای تفکیک شده (ظروف جداگانه) طبقهبندی و به صورت یک مدل معرفی میگردند. سپس با در نظر گرفتن ویژگیهای هر طبقه، شی جدید به آنها تخصیص یافته، برچسب و نوع آن پیشگویی میگردد.در طبقهبندی، مدل ایجاد شده بر پایهی یکسری دادههای آموزشی، (اشیا دادههایی که بر چسب کلاس آنها مشخص و شناخته شدهاست) حاصل میآید. مدل بدست آمده در اشکال گوناگون مانند قوانین طبقه بندی (If-Then)، درختهای تصمیم، فرمولهای ریاضی و شبکههای عصبی قابل نمایش میباشد. از طبقهبندی میتوان برای پیشگویی کلاس اشیا دادهها استفاده کرد. در برخی موارد نیز افراد ترجیح میدهند مقدار یک خصیصه و نه کلاس آن را پیشگویی نمایند که به یافتن مقدار یک خصیصه، پیشگویی اتلاق میگردد. در هر حال پیشگویی، تخمین مقدار و بر چسب کلاس را با هم در بر میگیرد. طبقهبندی و پیشگویی با استفاده از تحلیل ارتباط، خصیصههایی را که فرایند مورد نظر، بی تاثیر و قابل حذف میباشند، شناسایی میکنند.
طبقهبندی دادهها یک فرآیند دو مرحله ای است: 1-یادگیری 2–طبقهبندی
1-در مرحله اول یک مدل ساخته میشود که مجموعهای از کلاسهای دادهای یا مفاهیم را مشخص میکند. این مرحله را مرحله یادگیری گوییم که در ان یک الگوریتم طبقهبندی یک مدل را با تحلیل یک مجموعهی آموزشی که مجموعهای از تاپلهای پایگاه دادهاست میسازد و بر چسب کلاسهای مربوط به این تاپلها را مشخص میکند. یک تاپل X با یک بردار صفت (x1،x2،…،xn)-X نمایش داده میشود. فرض میشود که هر تاپل به یک کلاس از پیش تعریف شده متعلق است و کلاس با یک صفت که به آن صفت بر چسب کلاس میگوییم مشخص میشود. مجموعه آموزشی به صورت تصادفی از پایگاه انتخاب میشود. از آنجایی که برچسب هر تاپل آموزشی در این مرحله مشخص است، این مرحله یادگیری نظارت شده نامیده میشود. 2- در مرحله دوم، از مدل ساختهشده برای طبقهبندی استفاده میشود. یادگیری از طریق یک تابع (X)fy انجام میشود که میتواند برچسب کلاس هر تاپل X از پایگاه را پیشبینی کند. این تابع به صورت قواعد طبقهبندی، درختهای تصمیمگیری یا فرمولهای ریاضی است. شکل زیر نشان میدهد که چگونه یک تابع طبقهبندی ساخته شده و سپس دادههای جدید بوسیله آن طبقهبندی میشوند.
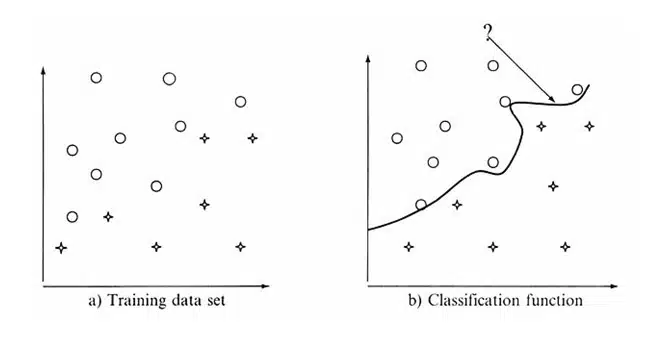
در ابتدا میزان دقت مدل یا کلاسهبند تخمین زده میشود. این تاپلها تصادفی انتخاب شده و مستقل از تاپلهای مجموعه آموزشی هستند. میزان دقت در پیشگویی یک مدل روی مجموعه تست دادهشده برابر است با درصد تاپلهایی از تاپلهای مجموعه تست که توسط مدل، درست طبقهبندی شدهاند. برچسب کلاس هر تاپل مجموعه تست، با برچسب کلاس پیشگویی شده برای آن تاپل توسط مدل یادگیری مقایسه میشود اگر میزان دقت مدل قابل قبول واقع شود، انگاه این مدل میتواند برای طبقهبندی تاپلهای جدید با بر چسب کلاس نامعلوم استفاده شود. (در اصطلاحات یادگیری ماشین به این نوع تاپلها یا دادهها unknown or previously unseen data گفته میشود).
انواع روشهای طبقهبندی
- استنتاج بر اساس درخت تصمیم
- طبقهبندی بیز
- شبکههای عصبی
- نزدیکترین همسایهها
- استنتاج مبتنی بر مورد
- الگوریتمهای ژنتیک
- مجموعههای فازی
ارزیابی روشهای طبقهبندی
ارزیابی روشهای طبقهبندی با معیارهای زیر انجام میپذیرد:
میزان دقت
Classifer accuracy: میزان قابلیت و توانایی یک مدل در پیشگویی صحیح بر چسب یک کلاس.
Predictor accuracy: میزان قابلیت و توانایی یک مدل در حدس مقدار صفتهای پیشگویی شده.
- سرعت و توسعه پذیری از نظر زمانی که برای ایجاد یک مدل و زمان استفاده از آن مدل لازم میباشد . این زمان شامل مدت زمان ساخت مدل (زمانیادگیری) و مدت زمان استفاده از مدل (زمان طبقه بندی/پیشگویی) میباشد.
- قوی بودن معیار مهمی است که میزان توانایی یک مدل را دربرخورد با نویز و مقادیر حذف شده تعیین میکند.
- توسعهپذیری معیار دیگری است که از نقطه نظر میزان کارایی در بانکهای اطلاعات بزرگ و نه دادههای مقیم در حافظه مورد بررسی قرار میگیرد.
- قابل تفسیر بودن یعنی میزان و سطح درک ایجاد شده توسط مدل از دیگر مواردی است که میبایست در بررسی روشهای طبقهبندی در نظر گرفت.
- سایر روشها از جمله شکل قوانین و نحوه نمایش انها از جمله سایز درخت تصمیم و فشردگی و پیوستگی.
بررسی انواع روشهای طبقهبندی
درخت تصمیم
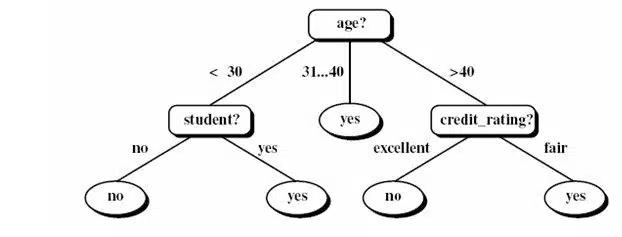
درخت تصمیم یکی از ابزارهای متداول برای دستهبندی و پیشبینی است. تولید یک درخت تصمیم روش کارآمدی برای ایجاد رده، بندها یا طبقهبندی کنندهها بر روی دادهها است. این درخت با بکارگیری یک استراتژی بالا به پایین به ایجاد آزمون بر روی هر گره میپردازد. با توجه به ساختار بالا به پایین درخت تصمیم اولین آزمون در گره ریشه که بالاترین گره در درخت است اتفاق میافتد به این صورت که یک رکورد جدید که برچسب کلاس آن نامشخص است در گره ریشه وارد میشود و در این گره یک آزمون صورت میگیرد تا معلوم شود که این رکورد به کدام یک از گرههای فرزند تعلق دارد. این فرایند آنقدر ادامه پیدا میکند تا رکورد جدید به گرهی برگ برسد. هر گرهی برگ در درخت تصمیم معرف یک برچسب کلاس یا یک دستهی مشخص میباشد. بنابراین تمام رکوردهایی که به یک برگ از درخت میرسند در یک دسته قرار میگیرند. نمونهای از درخت تصمیم در شکل زیر مشاهده میشود:
بیزین
الگوریتمهای یادگیری بیزی به طور صریح بر روی احتمالات فرضهای مختلف کار میکنند. کلاسهبندهای بیزی کلاسهبندهای آماری هستند. آنها اعضای کلاس را به صورت احتمالی پیشگویی میکنند. مثلاً میزان احتمال اینکه یک نمونه داده شده متعلق به یک کلاس خاص باشد. طبقهبندی بیزی بر مبنای تئوری بیز میباشد. مقایسه الگوریتمهای طبقهبندی نشان داده است که یک کلاسهبند بیزی ساده از نظر کارایی با کلاسه بندهای درخت تصمیم و شبکههای عصبی قابل رقابت است و در برخی موارد بهتر از انها عمل میکند. همچنین کلاسهبندهای بیزی میزان دقت و سرعت بالایی را هنگامی که در دیتابیسهای بزرگ به کار برده میشوند، ارائه میدهند. Naïve Bayesian classifier فرض میکند که تاثیر یک مقدار صفت روی یک کلاس دادهشده، مستقل از مقادیر دیگر صفتها میباشد. به این فرض استقلال شرطی کلاس گفتهمیشود. این فرض محاسبات را سادهتر میکند و به همین دلیل است که به این روش naïve گفته میشود. Bayesian belief network ها نیز که برای طبقهبندی استفاده میشوند، مدلهای گرافیکی هستند که بر خلاف naïve Baysian classifier ها وابستگی میان زیر مجموعهای از صفتها را نمایش میدهند.
روش طبقهبندی نزدیکترین K- همسایه
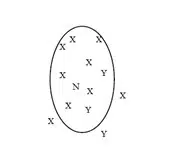
هنگام تلاش برای حل مسائل جدید، افراد معمولاً به راهحلهای مسائل مشابه که قبلاً حل شدهاند مراجعه میکنند. k- نزدیکترین همسایه (k-NN) یک تکنیک طبقهبندی است که از نسخهای از این متد استفاده میکند. در این روش تصمیمگیری اینکه یک نمونه جدید در کدام کلاس قرار گیرد با بررسی تعدادی (k) از شبیهترین نمونهها یا همسایهها انجام میشود. در بین این k نمونه، تعداد نمونه ها برای هر کلاس شمرده میشوند، و نمونه جدید به کلاسی که تعداد بیشتری از همسایهها به آن تعلق دارند نسبت داده میشود. شکل زیر محدوده همسایگی نمونه N را نشان میدهد. در این محدوده، بیشتر همسایهها در کلاس X قرار گرفتهاند.
اولین کار برای استفاده از k-NN یافتن معیاری برای شباهت یا فاصله بین صفات در دادهها و محاسبه آن است. در حالی که این عمل برای دادههای عددی آسان است، متغیرهای دستهای نیاز به برخورد خاصی دارند. هنگامی که فاصله بین نمونههای مختلف را توانستیم اندازه گیریم، میتوانیم مجموعه نمونههایی که قبلاً طبقهبندی شدهاند را به عنوان پایه دستهبندی نمونههای جدید استفاده کنیم. فهم مدلهای K-NN هنگامی که تعداد متغیرهای پیشبینی کننده کم است بسیار ساده است. آنها همچنین برای ساخت مدلهایی مانند متن که شامل انواع داده غیر استاندارد هستند، بسیار مفیدند. تنها نیاز برای انواع داده جدید وجود یک معیار مناسب شباهت است.
روش طبقهبندی شبکههای عصبی
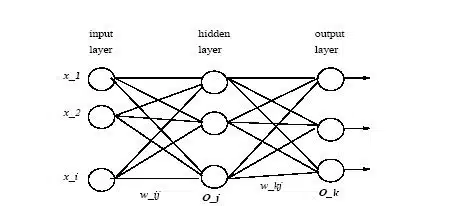
شبکه عصبی بوسیله الگوریتم پس انتشار خطا آموزش داده میشود. این شبکه از یک لایه ورودی، یک لایه خروجی و یک یا چند لایه نهان تشکیل شده است. هر گره در لایه ورودی معادل یکی از صفتهای نمونه ورودی میباشد و گرههای لایه خروجی نشان دهنده کلاسها هستند. هریال بین گرههای این لایهها دارای یک وزن میباشد که با یک مقدار تصادفی مقداردهی اولیه میشود (به عنوان مثال رنجی بین 1.0- تا 1.0 یا 0.5- تا 0.5). در طول مرحله یادگیری، شبکه با تنظیم این وزنها با استفاده از یک تابع آموزش و نمونه دادههای آموزشی، عمل یادگیری را انجام میدهد. الگوریتم طبقهبندی شبکه عصبی پرسپترون چند لایه (MLP)، اساس شبکههای عصبی جلو برنده میباشد. نمونهای از این شبکه دو لایهای در شکل زیر مشاهده میشود. جلو برنده، به این معنی است که مقدار پارامتر خروجی براساس پارامترهای ورودی و یک سری وزنهای اولیه تعیین میگردد. مقادیر ورودی با هم ترکیب شده و در لایههای نهان استفاده میشوند و مقادیر این لایههای نهان نیز برای محاسبه مقادیر خروجی ترکیب میشوند.
روش طبقهبندی ماشین بردار پشتیبان
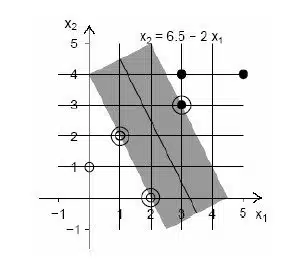
ماشین بردار پشتیبان (SVM) یکی از روشهای یادگیری ماشین است که از تئوری یادگیری آماری سرچشمه میگیرد و از آن برای طبقهبندی و رگرسیون استفاده میکنند. این روش از جمله روشهای نسبتاً جدیدی است که در سالهای اخیر کارایی خوبی برای طبقهبندی نسبت به روشهای قدیمیتر از جمله شبکههای عصبی پرسپترون نشان داده است. مبنای کاری طبقه بندی SVM، طبقه بندی خطی دادهها است. در تقسیم خطی دادهها سعی میشود خطی انتخاب شود که حاشیه اطمینان بیشتری داشته باشد. برای یک مسئله طبقه بندی دو کلاسه، هدف جداسازی دو کلاس بوسیله یک تابع است که از نمونههای آموزشی بدست میآید. شکل زیر یک مثال از یک مجموعه دادهی دو بعدی (دو کلاسه) را نشان میدهد که کلاسهای سیاه رنگ و سفید رنگ توسط خط x 2=6.5 – 2x 1 از هم جدا شدهاند. رنگ تیره در اطراف این خط، ماکزیمم حاشیهان خط را نشان میدهد.
شرکت نوین ایلیا صنعت از جمله شرکتهایی است که با دارا بودن نمایندگی رسمی برندهای فوقالعاده معتبری چون باسلر و سنسوپارت، نقش مهمی در زمینه طراحی و تولید سنسور پردازش تصویر و بهینهسازی فناوریهای مربوط به آن در ایران ایفا میکند. این شرکت با واردات قطعات و تجهیزات مطمئن و اورجینال به کشور، خدمات خود را به طرزی شایسته و با ضمانت معتبر به مشتریان خود ارائه مینماید. در حال حاضر شرکت نوین ایلیا صنعت در زمینه واردات فناوری پردازش تصویر، طراحی، پیادهسازی، نصب و راه اندازی سنسورها و ابزارها و دستگاههای لازم در این خصوص، به صورتی بی رقیب، پیشتاز میدان میباشد. در صورت نیاز به مشاوره در مورد این فناوری و یا هرگونه سوال درباره سنسور پردازش تصویر، ماشینهای بینایی، دوربینهای صنعتی و هوشمند کافی است با ما تماس بگیرید.





