شناسایی پلاک ایرانی: راهنمای جامع

مقدمهدر سالهای اخیر، پیشرفتهای چشمگیر در زمینهی بینایی ماشین (Machine Vision) و یادگیری عمیق (Deep Learning) امکان توسعهی سیستمهای خودکار شناسایی پلاک خودرو را به شدت تسهیل کرده است. شناسایی پلاک ایرانی یکی از چالشهای…
مقدمه
در سالهای اخیر، پیشرفتهای چشمگیر در زمینهی بینایی ماشین (Machine Vision) و یادگیری عمیق (Deep Learning) امکان توسعهی سیستمهای خودکار شناسایی پلاک خودرو را به شدت تسهیل کرده است. شناسایی پلاک ایرانی یکی از چالشهای خاص در این حوزه به شمار میآید؛ چرا که پلاکهای ایرانی علاوه بر حروف فارسی (و انگلیسی در برخی موارد) دارای قالب، رنگ و فونت مشخصی هستند و در شرایط نوری و زاویهی دید متنوع باید به درستی تشخیص داده شوند. در این مقالهی جامع، قصد داریم با تشریح مبانی و مراحل اصلی توسعهی یک سیستم شناسایی پلاک ایرانی در بینایی ماشین، از پیشپردازش تصویر تا استخراج و تشخیص کاراکترها را بررسی کنیم و مهمترین الگوریتمها، معماریها و تکنیکهای کاربردی را معرفی نماییم.
۱. اهمیت شناسایی پلاک در کاربردهای صنعتی و شهری
-
مدیریت ترافیک و کنترل سرعت: سیستمهای ANPR (Automatic Number Plate Recognition) به طور گسترده برای کنترل ترافیک، اندازهگیری سرعت متوسط و ثبت تخلفات رانندگی در شهرها استفاده میشوند.
-
پارکینگ هوشمند: در پارکینگهای عمومی و خصوصی، شناسایی خودکار پلاک خودرو امکان ورود و خروج بدون کارت یا اپراتور را فراهم میآورد.
-
امنیت و نظارت: در مراکز حساس مثل فرودگاهها، بنادر و ساختمانهای دولتی، ثبت خودکار پلاک خودروهای مجاز و مشکوک به بهبود سطح امنیت کمک میکند.
-
سیستمهای پرداخت عوارض جادهای: در آزادراهها، ایستگاههای عوارضی با خواندن پلاک خودرو، امکان پرداخت الکترونیکی بدون توقف را میسر میسازند.
۲. ساختار و مشخصات پلاک ایرانی
پلاکهای ملی ایران بر اساس استاندارد سازمان ثبت احوال و پلیس راهنمایی و رانندگی دارای ویژگیهای زیر هستند:
-
رنگبندی: پسزمینهی سفید، فونت مشکی یا زرد (در پلاکهای تجاری)
-
حروف فارسی: شامل حروف ششگانهی «الف»، «ب»، «پ»، «ت»، «ث»، «ج» و …
-
اعداد لاتین: چارچوب شش رقمی شامل سه رقم، یک حرف فارسی، و دو رقم دیگر
-
شکل و ابعاد: نسبت ابعادی مشخص (۴۰×۱۱ سانتیمتر برای پلاکهای ملی و ۳۵×۱۷ سانتیمتر برای پلاک شهر خودرو)
-
قطره و فواصل: فاصلهی استاندارد بین ارقام و حروف که هنگام طراحی شبکه عصبی باید مد نظر قرار گیرد.
درک این مشخصات برای طراحی الگوریتمهای مناسب شناسایی و تقسیمبندی کاراکترها ضروری است.
۳. چشمانداز کلی یک سیستم ANPR
یک سیستم شناسایی پلاک خودرو معمولاً از پنج مرحلهی اصلی تشکیل میشود:
-
پیشپردازش تصویر (Preprocessing): کاهش نویز، تصحیح روشنایی و کنتراست
-
کاوش پلاک (Plate Localization): یافتن ناحیهی پلاک در تصویر
-
تصحیح پرسپکتیو و برش (Perspective Correction & Cropping): تبدیل پلاک به نمای مستقیم و برش مستطیلی
-
تقسیمبندی کاراکترها (Character Segmentation): جداسازی حروف و اعداد از یکدیگر
-
تشخیص کاراکتر (Character Recognition): شناسایی حروف و اعداد با استفاده از شبکههای عصبی یا OCR کلاسیک
هر یک از این مراحل خود دارای جزئیات و تکنیکهای خاصی است که در ادامه به تفصیل به آنها میپردازیم.
۴. پیشپردازش تصویر
پیشپردازش تصویر اولین گام برای بهبود کیفیت ورودی به سیستم است:
-
تبدیل به سطح خاکستری (Grayscale): کاهش پیچیدگی محاسبات با حذف کانالهای رنگ
-
متدهای هموارسازی (Smoothing): مانند فیلتر گاوسی برای کاهش نویز
-
بهبود کنتراست (Contrast Enhancement): با CLAHE یا هیستوگرام اکولایزیشن
-
آستانهگذاری (Thresholding): تبدیل تصویر به دوتایی (Binary) برای جداسازی بهتر پلاک از پسزمینه
-
تصحیح روشنایی غیر یکنواخت (Illumination Correction): با استفاده از تکنیکهایی مانند بازتابگیری مورفولوژیک
این اقدامات به بهبود دقت مراحل بعدی کمک شایانی میکنند.
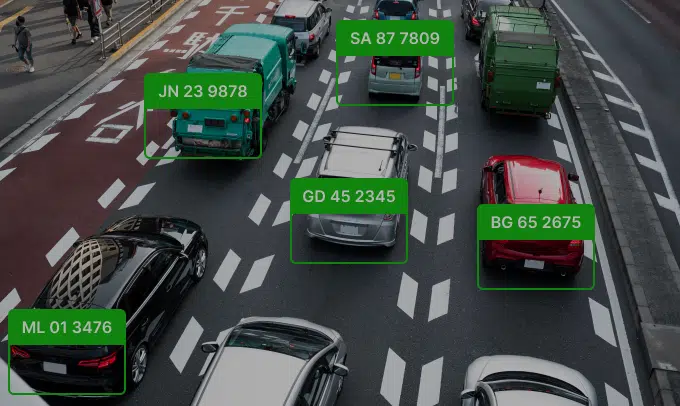
۵. تشخیص ناحیهی پلاک (Plate Localization)
تشخیص سریع و دقیق ناحیهی پلاک در تصویر اصلی، پایه و اساس کل سیستم است. چند رویکرد مرسوم عبارتاند از:
-
روشهای مبتنی بر کانتور (Contour-based):
-
یافتن کانتورهای مستطیلی با نسبت ابعاد مشخص
-
فیلتر کردن کانتورهای دارای ویژگیهای هندسی پلاک
-
-
ویژگیهای HOG+SVM:
-
استخراج ویژگیهای HOG (Histogram of Oriented Gradients)
-
طبقهبندی با SVM برای تشخیص ناحیهی پلاک
-
-
الگوریتمهای مبتنی بر یادگیری عمیق:
-
YOLO (You Only Look Once): تشخیص یکمرحلهای با سرعت بالا
-
SSD (Single Shot MultiBox Detector): تعادل سرعت و دقت
-
Faster R-CNN: دقت بالاتر و زمان پردازش بیشتر
-
در کاربردهای زمان واقعی، معمولاً از روشهای یکمرحلهای مثل YOLOv3/v4/v5 با وزنهای بهینه استفاده میشود تا هم سرعت و هم دقت به حد مطلوب برسد.
۶. تصحیح پرسپکتیو و برش (Perspective Correction)
پس از شناسایی جعبهی حاوی پلاک، نیاز است که پلاک به صورت افقی و بدون اعوجاج در تصویر برش بخورد:
-
تعیین چهار گوشهی مستطیل پلاک با استفاده از کانتور یا نقاط برتر تشخیص یافته توسط شبکه
-
محاسبهی همساز هندسی (Homography): برای تبدیل پرسپکتیو به نمای مستقیم
-
نمونهبرداری مجدد (Warping): با استفاده از تابع
warpPerspectiveدر OpenCV -
برش نهایی: تولید تصویر مستطیلی پلاک برای مراحل بعدی
این کار از بروز خطاهای جدی در تقسیمبندی کاراکترها جلوگیری میکند.
۷. تقسیمبندی کاراکترها (Character Segmentation)
در این مرحله، حروف و اعداد پلاک از یکدیگر جدا میشوند. تکنیکهای معمول عبارتند از:
-
آستانهگذاری تطبیقی (Adaptive Thresholding): برای جداسازی دقیقتر حروف از پسزمینه
-
حذف خطوط و نوار جداکننده: با حذف المانهای مورفولوژیک نازک
-
جداسازی بر اساس کانتور: شناسایی کانتور هر کاراکتر و استخراج باکس محدودکننده
-
تحلیل ویژگیهای هندسی: مانند نسبت ابعاد (Aspect Ratio)، مساحت و فاصله از مرکز
-
اصلاح همپوشانی و چسبندگی: با استفاده از عملیات مورفولوژیک باز و بسته
در برخی پیادهسازیهای پیشرفته، تقسیمبندی به صورت یکمرحلهای و درون مدلهای CNN/RNN نیز قابل ادغام است.
۸. تشخیص کاراکتر (Character Recognition)
پس از استخراج تکتک کاراکترها، نوبت به تشخیص آنها میرسد. دو رویکرد اصلی وجود دارد:
-
OCR کلاسیک:
-
Template Matching: مقایسه الگوهای ثابت حروف
-
OCR مبتنی بر Tesseract: تنظیم پارامترها و آموزش مدل برای فونتهای پلاک
-
-
شبکههای عصبی عمیق:
-
CNN ساده: برای تصاویر کاراکتر با اندازهی ثابت
-
CRNN (Convolutional Recurrent Neural Network): در کنار CNN از LSTM برای پردازش توالی کاراکترها
-
Attention-based Models: مانند Transformer برای توجه به بخشهای مختلف کاراکتر
-
مدلهای عمیق معمولاً دقت بالاتر (بیش از ۹۸٪) و تحمل به نویز را نسبت به روشهای کلاسیک ارائه میدهند.
۹. ارزیابی عملکرد و معیارها
برای سنجش کیفیت سیستم ANPR، معیارهای زیر به کار میروند:
-
دقت تشخیص پلاک (Plate Detection Accuracy): نسبت تصاویر صحیح تشخیصیافته
-
IoU (Intersection over Union): میزان همپوشانی پیشبینی و زمینواقعی
-
دقت OCR: درصد کاراکترهای بهدرستی شناساییشده
-
Word Accuracy / Plate Accuracy: درصد پلاکهای کامل که بدون خطا شناسایی شدهاند
-
زمان پردازش میانگین: برای اطمینان از کارایی در زمان واقعی
برای بهینهسازی، معمولاً مجموعه دادههای آزمون شامل تصاویر ثبتشده در نور و زاویههای مختلف استفاده میشود.
۱۰. مجموعه دادهها و آمادهسازی (Datasets & Augmentation)
برای آموزش و سنجش مدلهای شناسایی پلاک ایرانی، باید از دیتاستهای استاندارد یا مجموعه دادهی سفارشی بهره برد:
-
Iranian License Plate Dataset: شامل هزاران تصویر پلاک ایرانی در شرایط نوری و آب و هوایی متنوع
-
دادهافزایی (Data Augmentation): چرخش، تغییر روشنایی، نویز، افکت باران/برف
-
تصاویر مصنوعی (Synthetic Data): تولید پلاکهای مجازی با فونت و رنگ استاندارد برای افزایش تنوع
-
تقسیمبندی داده: جداسازی مجموعهی آموزش، اعتبارسنجی و آزمون (مثلاً ۷۰/۱۵/۱۵)
این اقدامات به جلوگیری از بیشبرازش (Overfitting) و بهبود قابلیت تعمیم مدل کمک میکنند.
۱۱. چالشها و راهکارها
-
تغییرات نور و سایه: با استفاده از نورسنجی پویا و فیلترهای اصلاح روشنایی
-
زاویه دید نامطلوب: ترکیب چند فریم و ردیابی حرکت برای بهبود ثبات
-
کثیفی یا آسیب پلاک: استفاده از تکنیکهای تصحیح تصویر و مدلهای مقاوم به نویز
-
پلاکهای غیراستاندارد (مثلاً پلاکهای مناطق خاص): آموزش مدل با نمونههای متنوع
-
محدودیت منابع سختافزاری در اجرا بر لبه (Edge): بهینهسازی مدل، کمینهسازی پارامترها و کوانتیزهسازی
با انتخاب معماری و مراحل پیشپردازش مناسب میتوان این چالشها را برطرف نمود.
۱۲. پیادهسازی بر روی سختافزار لبه (Edge Deployment)
اجرای سیستم ANPR بر روی دستگاههای لبه (Edge Devices) مثل NVIDIA Jetson یا Raspberry Pi به کاهش تأخیر کمک میکند:
-
کوانتیزهسازی مدل (Quantization): کاهش حجم مدل و مصرف حافظه
-
انتشار بهینهشده (Pruning): حذف اتصالات کماهمیت در شبکه عصبی
-
فریمورکهای سبک: TensorRT، ONNX Runtime Mobile
-
تعامل با دوربینهای شبکهای (IP Cameras): جریان ویدئویی بلادرنگ و ارسال نتایج به سرور مرکزی
این رویکرد برای کاربردهای تلفن همراه و سیستمهای مستقل ایدهآل است.

۱۳. کاربردهای ویژه در ایران
-
پلاک مناطق آزاد: با توجه به قالب متفاوت برخی پلاکها، نیاز به قاعدهگذاری مجزا
-
پلاکهای موقت و ترانزیت: فونت و رنگ متفاوت که باید در مدل گنجانده شود
-
کنترل پارک حریم خصوصی: تنظیم مجوزها بر اساس مالکیت خودرو
-
سامانههای مدیریت حملونقل عمومی: تخصیص حقوق عبور و مرور به تاکسیها و اتوبوسها
ادغام با سامانههای دولتی و رعایت مقررات حریم خصوصی برای پیادهسازی موفق ضروری است.
۱۴. آینده پژوهشی و گامهای بعدی
-
استفاده از معماریهای Transformer و Vision Transformer: برای بهبود توجه به جزئیات کاراکتر
-
یادگیری تفاضلی (Few-shot Learning): شناسایی پلاکهای جدید با دادهی محدود
-
شبکههای نسل بعد (e.g. YOLOv7, YOLOX): افزایش سرعت و دقت تشخیص
-
فیوژن چندحسی (Sensor Fusion): ترکیب دوربین IR و دوربین RGB برای بهبود کارایی در شب
-
یادگیری مشترک (Federated Learning): آموزش مدلهای مشترک بین چند سازمان بدون افشای دادهی خصوصی
این روندها چشمانداز روشنی برای افزایش دقت و انعطافپذیری سیستمهای ANPR در ایران فراهم میکنند.
۱۵. نتیجهگیری
شناسایی پلاک ایرانی در بینایی ماشین مجموعهای از مراحل فنی و چالشهای خاص است که با توجه به ساختار پلاکهای داخلی و شرایط محیطی ایران، نیاز به دقت بالا و طراحی حسابشده دارد. از پیشپردازش تصویر و تشخیص ناحیهی پلاک تا تقسیمبندی کاراکتر و OCR عمیق، هر کدام بخش مهمی از سامانه را تشکیل میدهند. با بهرهگیری از روشهای مبتنی بر یادگیری عمیق، دادهافزایی هوشمند و معماریهای نوین، میتوان سیستمهایی با دقت بالای بیش از ۹۹٪ و زمان پردازش بلادرنگ ایجاد کرد. این فناوری ضمن تسهیل مدیریت ترافیک، افزایش امنیت و بهبود تجربه کاربری در پارکینگها و سامانههای پرداخت عوارض، افق جدیدی در حملونقل هوشمند ایران گشوده است.





