راهنمایی مقدماتی به بخشبندی معنایی در بینایی ماشین

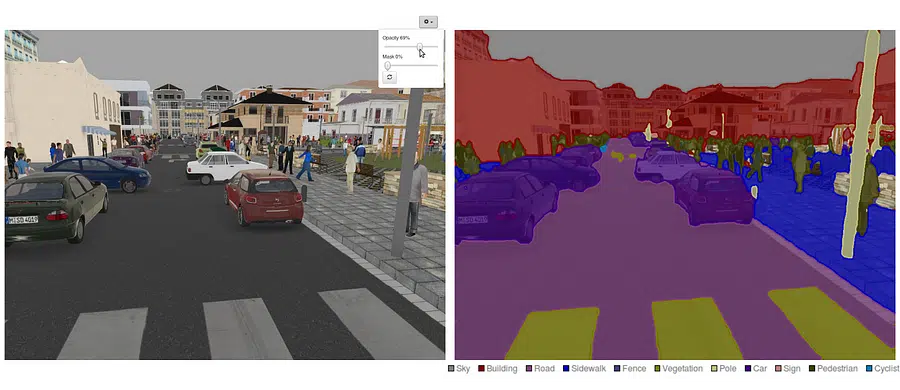
بخشبندی معنایی (Semantic Segmentation) به معنای برچسبگذاری هر پیکسل در یک تصویر با یک کلاس خاص است، به عبارتی دیگر، “رنگآمیزی” دقیق هر پیکسل با توجه به چیزی که نمایش میدهد. برخلاف دستهبندی تصویر (Image…
بخشبندی معنایی (Semantic Segmentation) به معنای برچسبگذاری هر پیکسل در یک تصویر با یک کلاس خاص است، به عبارتی دیگر، “رنگآمیزی” دقیق هر پیکسل با توجه به چیزی که نمایش میدهد. برخلاف دستهبندی تصویر (Image Classification) که فقط میگوید “این تصویر یک گربه دارد” یا تشخیص اشیاء (Object Detection) که دور هر شیء یک کادر میکشد، در بخشبندی معنایی، یک نقاب (ماسک) روی تصویر کشیده میشود که نشان میدهد دقیقاً کدام پیکسلها متعلق به گربه، میز، آسمان و غیره هستند.
تفاوت بین وظایف اصلی در بینایی ماشین
-
دستهبندی تصویر: یک برچسب به کل تصویر اختصاص میدهد (مثلاً “گربه” یا “سگ”).
-
تشخیص اشیاء: با کشیدن کادر دور اشیاء، آنها را شناسایی و برچسبگذاری میکند.
-
بخشبندی معنایی: به هر پیکسل یک کلاس اختصاص میدهد؛ در نتیجه، یک ماسک دقیق داریم که نشان میدهد هر بخش از تصویر به کدام دسته تعلق دارد.
بخشبندی معنایی اطلاعات بسیار دقیقتری نسبت به سایر وظایف فراهم میکند و شکل دقیق اشیاء و نواحی پسزمینه را مشخص میسازد. در حقیقت، میتوان آن را نوعی دستهبندی در سطح پیکسل در نظر گرفت.
بخشبندی معنایی چگونه کار میکند؟
به صورت کلی، بخشبندی معنایی از یک شبکه عصبی کانولوشنی (CNN) استفاده میکند که تصویری را به عنوان ورودی میگیرد و خروجیای با همان ابعاد تصویر تولید میکند که در آن هر پیکسل، دارای یک مقدار است که نمایانگر کلاس پیشبینیشده است.
مراحل اصلی:
-
پیشپردازش: تغییر اندازه تصاویر، نرمالسازی مقدار پیکسلها (مانند مقیاسبندی به بازه 0 تا 1)، و اعمال افزایش داده (چرخش، وارونهسازی، تغییر روشنایی). برچسب صحیح هر تصویر نیز به صورت یک ماسک بخشبندی است که هر پیکسل دارای عددی است که نشاندهنده کلاس آن پیکسل است.
-
گذر رو به جلو (Forward Pass): شبکه CNN تصویر را پردازش کرده و ویژگیهایی از آن استخراج میکند. برخلاف دستهبندی، در اینجا از لایههای Fully Connected استفاده نمیشود تا اطلاعات مکانی حفظ شود. خروجی معمولاً یک آرایه 3بعدی با ابعاد (تعداد کلاسها، ارتفاع، عرض) است.
-
بزرگنمایی (Upsampling): چون CNNها معمولاً با pooling اندازه تصویر را کاهش میدهند، باید خروجی را دوباره به اندازه اصلی بازگرداند. این کار با کانولوشن ترانهاده (Transpose Convolution)، درونیابی (Interpolation) یا روشهایی مانند unpooling (در مدلهایی مانند SegNet) انجام میشود.
-
ماسک خروجی: پس از بزرگنمایی، از یک softmax پیکسلبهپیکسل برای انتخاب کلاس نهایی هر پیکسل استفاده میشود. خروجی نهایی یک نقشه دوبعدی است که نشان میدهد هر پیکسل به کدام کلاس تعلق دارد.

مدلهای معروف بخشبندی معنایی
U-Net
مدلی با ساختار U شکل که از رمزگذار و رمزگشا تشکیل شده است. از skip connection برای ترکیب اطلاعات دقیق و اطلاعات کلی استفاده میکند. در ابتدا برای تصاویر پزشکی توسعه یافت اما اکنون در بسیاری از کاربردها استفاده میشود.
SegNet
ساختاری مشابه با رمزگذار VGG دارد. ویژگی خاص آن ذخیره ایندکسهای max-pooling است که برای unpooling در رمزگشا استفاده میشود تا موقعیت فضایی پیکسلها حفظ شود.
DeepLab
مبتنی بر کانولوشنهای Atrous (گشاد شده) است که به شبکه اجازه میدهد بدون کاهش وضوح، اطلاعات بیشتری از بافت تصویر بگیرد. DeepLabV3 با استفاده از ASPP چندین کانولوشن با نرخهای مختلف را به کار میگیرد تا اطلاعات مقیاسهای مختلف را استخراج کند.
کاربردهای دنیای واقعی
-
وسایل نقلیه خودران: برای تشخیص جاده، عابر پیاده، خودروها و علائم.
-
تصویربرداری پزشکی: برای تفکیک نواحی مختلف بدن یا تومورها در MRI و CT.
-
کشاورزی و سنجش از دور: برای تشخیص نوع پوشش زمین از تصاویر هوایی (آب، گیاه، خاک، ساختمان).
-
رباتیک و تولید صنعتی: در تشخیص قطعات، شناسایی عیوب، یا جداسازی اشیاء برای بازوی رباتیک.
-
واقعیت افزوده: برای جدا کردن افراد از پسزمینه و اعمال افکتهای زنده.
دادهها و ابزارها
مجموعه دادههای معروف:
-
Cityscapes: صحنههای شهری با ۵۰ شهر و بیش از ۵۰۰۰ تصویر دارای برچسب دقیق.
-
PASCAL VOC 2012: شامل ۲۰ کلاس شیء و برچسبگذاری در سطح پیکسل.
-
ADE20K: شامل ۱۵۰ کلاس در صحنههای داخلی و خارجی.
-
COCO-Stuff: افزودنی برای مجموعه COCO برای برچسبگذاری موارد غیرشیء مانند آسمان، چمن و غیره.
-
CamVid: مجموعه دادهای کوچکتر برای صحنههای رانندگی.
ابزارها و کتابخانهها:
-
TensorFlow و PyTorch: دو چارچوب محبوب برای پیادهسازی شبکههای بخشبندی.
-
segmentation-models.pytorch: کتابخانهای با مدلهای آماده مانند U-Net و DeepLab.
-
OpenCV: برای روشهای کلاسیک مانند GrabCut.
-
ابزارهای برچسبگذاری: مانند LabelMe و CVAT برای تولید ماسکهای برچسبدار.
نکات کلیدی برای شروع
-
بدون نیاز به ریاضی سنگین: فقط مفاهیم کلی را یاد بگیرید، نه فرمولها.
-
پیشپردازش مناسب: تصویر و ماسک را با هم تغییر دهید.
-
خروجی مدل: معمولاً یک آرایه سهبعدی است که با softmax به برچسب نهایی هر پیکسل میرسد.
-
ارزیابی عملکرد: با معیارهایی مثل IoU یا mean IoU.
-
پروژههای ساده برای تمرین: مانند دیتاست Oxford Pet برای تمرین با U-Net.
نتیجهگیری
بخشبندی معنایی در واقع همان دستهبندی است اما در سطح پیکسل. با استفاده از ابزارها و چارچوبهای آماده، حتی مبتدیان نیز میتوانند مدلهایی بسازند که تصاویر را بهصورت دقیق ماسک میکنند. شروع کار با پروژههای ساده و تمرین مداوم، کلید موفقیت در این زمینه است.





