شبکه عصبی پردازش تصویر: راهنمای جامع از مبانی تا کاربردهای پیشرفته (۲۰۲۵)

دنیای ما مملو از دادههای بصری است. از تصاویری که در شبکههای اجتماعی به اشتراک میگذاریم تا ویدیوهای دوربینهای نظارتی و تصاویر پزشکی پیچیده. اما چگونه میتوانیم به ماشینها یاد بدهیم این حجم عظیم از…
دنیای ما مملو از دادههای بصری است. از تصاویری که در شبکههای اجتماعی به اشتراک میگذاریم تا ویدیوهای دوربینهای نظارتی و تصاویر پزشکی پیچیده. اما چگونه میتوانیم به ماشینها یاد بدهیم این حجم عظیم از اطلاعات را «ببینند»، «درک کنند» و از آن برای تصمیمگیری استفاده نمایند؟ پاسخ در یکی از انقلابیترین فناوریهای عصر ما نهفته است: شبکه عصبی پردازش تصویر.
پردازش تصویر (Image Processing) حوزهای است که دههها قدمت دارد، اما ظهور یادگیری عمیق (Deep Learning) و بهویژه شبکههای عصبی کانولوشن (CNN)، این رشته را از یک حوزه تخصصی به یک فناوری فراگیر تبدیل کرده است که در گوشی هوشمند شما، خودروهای خودران و پیشرفتهترین ابزارهای پزشکی حضور دارد.
در این مقاله جامع، سفری عمیق به دنیای شگفتانگیز شبکه عصبی پردازش تصویر خواهیم داشت. فرقی نمیکند یک دانشجو، یک توسعهدهنده، یک مدیر محصول یا فقط یک فرد کنجکاو باشید؛ این راهنما تمام چیزی است که برای درک این فناوری نیاز دارید.
۱. گذار از سنت به مدرنیته: چرا پردازش تصویر سنتی کافی نبود؟
قبل از ظهور شبکههای عصبی، مهندسان برای تحلیل تصاویر به روشهای «دستی» متکی بودند. در این روشها که به «پردازش تصویر کلاسیک» معروفاند، متخصصان الگوریتمهایی را برای استخراج ویژگیهای خاصی از تصویر طراحی میکردند. برای مثال:
- فیلترهای لبهیاب (Edge Detection): الگوریتمهایی مانند Sobel، Canny و Prewitt برای شناسایی لبهها و مرزهای اشیاء در تصویر استفاده میشدند.
- استخراج ویژگی (Feature Extraction): الگوریتمهای پیچیدهتری مانند SIFT و SURF برای شناسایی «نقاط کلیدی» (مانند گوشهها) در تصویر به کار میرفتند تا بتوان اشیاء را حتی در صورت چرخش یا تغییر مقیاس شناسایی کرد.
مشکل اصلی کجا بود؟ این روشها بسیار شکننده و محدود بودند. مهندس باید بهصورت دستی ویژگیهای مورد نظر را تعریف میکرد. برای مثال، برای تشخیص گربه، باید به کامپیوتر میگفتیم دنبال گوشهای نوکتیز، سبیل و چشمهای گرد بگردد. اما اگر گربه در زاویهای متفاوت قرار میگرفت، نور محیط تغییر میکرد یا نژاد گربه متفاوت بود، کل سیستم به مشکل برمیخورد.
انقلاب شبکههای عصبی در این بود که فرآیند استخراج ویژگی را خودکار کرد. بهجای اینکه به شبکه بگوییم دنبال چه چیزی بگردد، ما هزاران تصویر از گربهها را به آن نشان میدهیم و شبکه عصبی خودش یاد میگیرد که ویژگیهای کلیدی یک گربه چیست. این تغییر پارادایم از «مهندسی ویژگی دستی» به «یادگیری ویژگی خودکار» دلیل اصلی قدرت بینظیر شبکههای عصبی مدرن است.

نکته کلیدی: شبکههای عصبی بهجای پیروی از دستورالعملهای ثابت، از طریق مثالها (دادهها) یاد میگیرند و همین ویژگی آنها را برای دنیای پیچیده و غیرقابل پیشبینی واقعی بسیار قدرتمند میسازد.
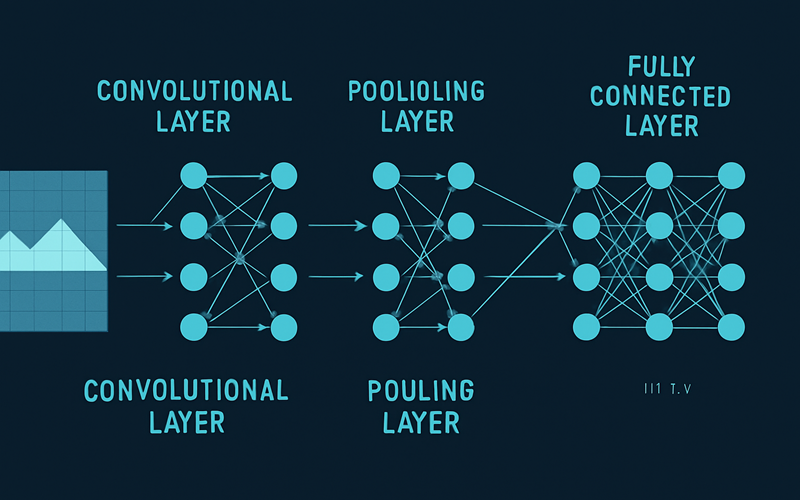
۲. معماری انقلابی: شبکه عصبی کانولوشن (CNN) چیست و چگونه کار میکند؟
وقتی صحبت از شبکه عصبی پردازش تصویر میشود، اولین و مهمترین مفهومی که باید با آن آشنا شویم، شبکه عصبی کانولوشن (Convolutional Neural Network – CNN) است. CNN نوع خاصی از شبکه عصبی است که از ساختار بیولوژیکی قشر بینایی مغز الهام گرفته شده و برای پردازش دادههای شبکهمانند (Grid-like Data) مانند تصاویر، بهینهسازی شده است.
یک تصویر برای کامپیوتر، ماتریسی از اعداد (پیکسلها) است. یک CNN با اعمال فیلترها و عملیات ریاضی روی این ماتریس، الگوهای مختلفی را از سطح پایین (لبهها و رنگها) تا سطح بالا (اشکال پیچیده و اشیاء) شناسایی میکند.
بیایید اجزای اصلی یک CNN را کالبدشکافی کنیم:
لایه کانولوشن (Convolutional Layer): چشمهای شبکه
این لایه، قلب تپنده یک CNN است. عملکرد آن شبیه به حرکت یک ذرهبین روی یک صفحه بزرگ است. این «ذرهبین» که در اصطلاح فنی فیلتر (Filter) یا کِرنِل (Kernel) نامیده میشود، یک ماتریس عددی کوچک است. فیلتر روی تمام قسمتهای تصویر ورودی حرکت کرده و در هر موقعیت، یک عملیات ریاضی به نام «کانولوشن» انجام میدهد.
- هدف: هر فیلتر برای شناسایی یک ویژگی خاص طراحی شده است. برای مثال، یک فیلتر ممکن است لبههای عمودی را شناسایی کند، فیلتری دیگر لبههای افقی و فیلتری دیگر یک طیف رنگی خاص را.
- خروجی: خروجی این لایه، مجموعهای از نقشههای ویژگی (Feature Maps) است که هر کدام نشاندهنده حضور یک ویژگی خاص در نقاط مختلف تصویر ورودی است. در لایههای ابتدایی، این ویژگیها ساده (مانند لبه و بافت) هستند و در لایههای عمیقتر، با ترکیب این ویژگیهای ساده، الگوهای پیچیدهتری (مانند چشم، بینی یا چرخ ماشین) شناسایی میشوند.
تابع فعالسازی (Activation Function): معرفی غیرخطی بودن
بعد از هر لایه کانولوشن، یک تابع فعالسازی اعمال میشود. محبوبترین تابع در CNNها، ReLU (Rectified Linear Unit) است. کار این تابع بسیار ساده است: هر عدد منفی را صفر میکند و هر عدد مثبت را بدون تغییر باقی میگذارد.
- چرا این کار مهم است؟ دنیای واقعی پر از پدیدههای غیرخطی است. اگر از توابع فعالسازی استفاده نکنیم، کل شبکه عصبی ما به یک مدل خطی ساده تبدیل میشود که قادر به یادگیری الگوهای پیچیده نخواهد بود. ReLU به شبکه اجازه میدهد تا روابط بسیار پیچیدهتری را در دادهها یاد بگیرد.

لایه تجمعی (Pooling Layer): هوشِ خلاصهسازی
بعد از استخراج ویژگیها در لایه کانولوشن، معمولاً یک لایه تجمعی (یا نمونهکاهی – Subsampling) قرار میگیرد. هدف این لایه، کاهش ابعاد نقشههای ویژگی و در نتیجه، کاهش بار محاسباتی است.
- چگونه کار میکند؟ رایجترین نوع آن Max Pooling است. این لایه، نقشه ویژگی را به بخشهای کوچک تقسیم کرده و از هر بخش، فقط بزرگترین مقدار را نگه میدارد و بقیه را حذف میکند.
- مزایا:
- کاهش ابعاد: حجم دادهها را کم میکند که باعث افزایش سرعت محاسبات میشود.
- کنترل بیشبرازش (Overfitting): با حذف اطلاعات جزئی، به مدل کمک میکند تا روی ویژگیهای مهمتر تمرکز کند.
- ایجاد ناوردایی نسبت به انتقال (Translation Invariance): باعث میشود که اگر یک ویژگی کمی در تصویر جابجا شود، باز هم توسط شبکه شناسایی گردد.
لایه تماماً متصل (Fully Connected Layer): مغزِ تصمیمگیرنده
پس از چندین لایه کانولوشن و تجمعی، نقشههای ویژگی نهایی که حاوی اطلاعات سطح بالا هستند، به یک یا چند لایه تماماً متصل (FC) وارد میشوند. این لایهها شبیه به شبکههای عصبی معمولی هستند که در آنها هر نورون به تمام نورونهای لایه قبلی متصل است.
- وظیفه: این لایه، ویژگیهای استخراجشده را دریافت کرده و وظیفه نهایی مانند طبقهبندی (Classification) را انجام میدهد. برای مثال، بر اساس ویژگیهایی مانند «گوش»، «چشم» و «بینی»، تصمیم میگیرد که تصویر ورودی با احتمال ۹۵٪ گربه است.
مسیر یک تصویر در CNN:
تصویر ورودی->[کانولوشن -> ReLU -> تجمعی]->[کانولوشن -> ReLU -> تجمعی]-> … ->لایه تماماً متصل->خروجی (مثلاً: گربه، سگ)
۳. غولهای تاریخساز: مشهورترین معماریهای CNN که دنیا را تغییر دادند
در طول سالها، محققان معماریهای مختلفی از CNN را طراحی کردهاند که هر کدام در زمان خود یک پیشرفت بزرگ محسوب میشدند. آشنایی با این مدلها برای درک عمیقتر حوزه ضروری است:
- LeNet-5 (1998): یکی از اولین CNNهای موفق که توسط Yann LeCun برای تشخیص ارقام دستنویس در چکهای بانکی طراحی شد. این مدل، پدر تمام CNNهای مدرن محسوب میشود.
- AlexNet (2012): این معماری، لحظه «انفجار بزرگ» یادگیری عمیق بود. AlexNet با پیروزی قاطعانه در مسابقه معتبر ImageNet، به دنیا نشان داد که شبکههای عصبی عمیق چقدر قدرتمند هستند. نوآوریهای کلیدی آن شامل استفاده از تابع ReLU، تکنیک Dropout برای جلوگیری از بیشبرازش و آموزش روی GPUها بود.
- VGGNet (2014): این مدل نشان داد که عمق شبکه یک فاکتور بسیار مهم است. VGGNet با استفاده از فیلترهای بسیار کوچک (۳x۳) و چیدن آنها در لایههای بسیار عمیق (۱۶ تا ۱۹ لایه)، به نتایج فوقالعادهای دست یافت.
- GoogLeNet (Inception) (2014): این معماری که توسط گوگل توسعه یافت، بهجای عمیقتر کردن شبکه، آن را «عریضتر» کرد. با استفاده از «ماژولهای Inception»، این شبکه میتوانست با محاسبات بسیار کمتر، نتایج بهتری نسبت به VGGNet کسب کند.
- ResNet (Residual Network) (2015): این مدل یک مشکل اساسی در شبکههای بسیار عمیق را حل کرد: مشکل محو شدن گرادیان (Vanishing Gradient). با معرفی «اتصالات میانبر» (Skip Connections)، ResNet به شبکهها اجازه داد تا عمقی بیسابقه (بیش از ۱۵۰ لایه) داشته باشند و رکوردهای دقت را در هم بشکنند.
- U-Net (2015): یک معماری تخصصی برای بخشبندی تصاویر پزشکی (Medical Image Segmentation). ساختار متقارن آن (شبیه به حرف U) به آن اجازه میدهد تا اطلاعات مکانی دقیق را برای بخشبندی پیکسلبهپیکسل حفظ کند.
- YOLO (You Only Look Once): این معماری، انقلابی در حوزه تشخیص اشیاء آنی (Real-time Object Detection) ایجاد کرد. برخلاف مدلهای قبلی، YOLO کل تصویر را فقط یک بار میبیند و در یک مرحله، تمام اشیاء و موقعیت آنها را شناسایی میکند که آن را بسیار سریع میسازد.
۴. از تئوری تا واقعیت: کاربردهای شگفتانگیز شبکههای عصبی در پردازش تصویر
قدرت واقعی شبکه عصبی پردازش تصویر در کاربردهای عملی آن نهفته است. این فناوری در حال تغییر صنایع مختلف است:
طبقهبندی تصویر (Image Classification)
سادهترین و بنیادیترین وظیفه: به شبکه یک تصویر میدهیم و از آن میخواهیم بگوید تصویر متعلق به کدام دسته است.
- مثالها: تشخیص نژاد سگ، شناسایی نوع گل، فیلتر کردن محتوای نامناسب.
تشخیص و مکانیابی اشیاء (Object Detection & Localization)
این وظیفه یک پله فراتر از طبقهبندی است. شبکه نهتنها باید بگوید چه اشیائی در تصویر وجود دارند، بلکه باید موقعیت دقیق آنها را با یک کادر (Bounding Box) مشخص کند.
- مثالها: خودروهای خودران (شناسایی عابران پیاده، خودروها و علائم راهنمایی)، سیستمهای نظارتی هوشمند، مدیریت انبار.
بخشبندی تصویر (Image Segmentation)
این وظیفه دقیقترین سطح درک تصویر است. در اینجا، هر پیکسل از تصویر به یک دسته خاص اختصاص داده میشود.
- بخشبندی معنایی (Semantic Segmentation): تمام پیکسلهای متعلق به «جاده» را یک رنگ و تمام پیکسلهای «آسمان» را رنگ دیگری میکند.
- بخشبندی نمونهای (Instance Segmentation): نهتنها پیکسلهای «خودرو» را مشخص میکند، بلکه بین «خودرو ۱» و «خودرو ۲» تمایز قائل میشود.
- مثالها: پردازش تصاویر پزشکی (جداسازی تومور از بافت سالم)، ویرایش تصویر در گوشیهای هوشمند (جدا کردن فرد از پسزمینه).
تولید و ویرایش تصویر (Image Generation and Editing)
با ظهور شبکههای مولد تخاصمی (GANs)، شبکههای عصبی اکنون میتوانند تصاویر جدید و واقعگرایانه خلق کنند.
- مثالها: تولید چهرههای انسانی که وجود خارجی ندارند (StyleGAN)، انتقال سبک (تبدیل یک عکس به نقاشی ونگوگ)، افزایش کیفیت تصاویر (Super-Resolution)، رنگی کردن عکسهای سیاه و سفید.
تشخیص و بازشناسی چهره (Face Detection and Recognition)
این فناوری در بسیاری از سیستمهای امنیتی و کاربردهای روزمره استفاده میشود.
- مثالها: باز کردن قفل گوشی با چهره، تگ کردن خودکار افراد در فیسبوک، سیستمهای حضور و غیاب.
۵. چگونه اولین شبکه عصبی پردازش تصویر خود را بسازیم؟ (راهنمای عملی)
ساختن یک مدل پردازش تصویر دیگر یک رویای دور از دسترس نیست. با ابزارهای مدرن، این فرآیند بسیار سادهتر شده است. مراحل اصلی به شرح زیر است:
-
جمعآوری و آمادهسازی داده (Data Collection & Preparation):
- مجموعه داده (Dataset): شما به یک مجموعه داده بزرگ و برچسبخورده نیاز دارید. میتوانید از دیتاستهای معروفی مانند CIFAR-10، ImageNet یا COCO استفاده کنید یا دیتاست خود را بسازید.
- افزونگی داده (Data Augmentation): برای جلوگیری از بیشبرازش و افزایش تنوع دادهها، میتوانید تصاویر موجود را با عملیاتی مانند چرخش، برش، تغییر رنگ و زوم، بهصورت مصنوعی افزایش دهید.
-
انتخاب معماری و فریمورک:
- فریمورکها: محبوبترین ابزارها برای این کار TensorFlow (با Keras) و PyTorch هستند که هر دو بر پایه زبان برنامهنویسی پایتون کار میکنند.
- یادگیری انتقالی (Transfer Learning): بهجای ساختن یک شبکه از صفر، میتوانید از یک مدل از پیش آموزشدیده (مانند ResNet یا VGG که روی دیتاست ImageNet آموزش دیدهاند) استفاده کنید و فقط لایههای نهایی آن را برای وظیفه خاص خودتان دوباره آموزش دهید. این روش به دادههای کمتر و زمان آموزش کوتاهتری نیاز دارد و معمولاً نتایج بهتری میدهد.
-
آموزش مدل (Training):
- در این مرحله، مدل روی دادههای آموزشی اجرا میشود. با استفاده از الگوریتمهایی مانند پسانتشار (Backpropagation) و بهینهسازها (Optimizers) مانند Adam، وزنهای شبکه بهتدریج تنظیم میشوند تا تابع هزینه (Loss Function) (که خطای مدل را اندازهگیری میکند) به حداقل برسد.
-
ارزیابی و بهینهسازی (Evaluation & Tuning):
- پس از آموزش، عملکرد مدل روی دادههای آزمایشی (که مدل قبلاً ندیده) با معیارهایی مانند دقت (Accuracy)، Precision و Recall سنجیده میشود. در صورت نیاز، هایپرپارامترهای مدل (مانند نرخ یادگیری یا تعداد لایهها) برای رسیدن به نتیجه بهتر تنظیم میشوند.

۶. چالشها و افقهای آینده: مسیر پیش رو چیست؟
با وجود تمام پیشرفتها، حوزه شبکه عصبی پردازش تصویر هنوز با چالشهایی روبرو است:
- نیاز به دادههای حجیم: آموزش مدلهای دقیق نیازمند دیتاستهای بسیار بزرگ و برچسبخورده است که تهیه آنها پرهزینه و زمانبر است.
- نیاز به توان محاسباتی بالا: آموزش شبکههای عمیق به سختافزارهای قدرتمند (GPU) نیاز دارد.
- تفسیرپذیری (مشکل جعبه سیاه): درک اینکه یک شبکه عصبی دقیقاً چگونه به یک تصمیم خاص میرسد، هنوز یک چالش بزرگ است.
- حملات تخاصمی (Adversarial Attacks): میتوان با ایجاد تغییرات جزئی و نامحسوس در یک تصویر، یک شبکه عصبی پیشرفته را کاملاً فریب داد.
با این حال، آینده این حوزه بسیار روشن و هیجانانگیز است. روندهای کلیدی آینده عبارتند از:
- یادگیری با دادههای کمتر (Few-Shot & Zero-Shot Learning): توسعه مدلهایی که بتوانند با تعداد بسیار کمی مثال یا حتی بدون هیچ مثالی، یک مفهوم جدید را یاد بگیرند.
- مدلهای بهینه برای لبه (Edge AI): طراحی شبکههای عصبی سبک و کارآمد که بتوانند مستقیماً روی دستگاههای با توان محاسباتی کم (مانند گوشیهای هوشمند یا دوربینهای صنعتی) اجرا شوند.
- هوش مصنوعی قابل توضیح (Explainable AI – XAI): ایجاد تکنیکهایی برای فهم بهتر تصمیمات مدلهای عصبی.
- مدلهای پایهای (Foundation Models): توسعه مدلهای غولپیکر چندوجهی (Multimodal) که میتوانند بهطور همزمان تصویر، متن و صدا را درک کنند و وظایف بسیار متنوعی را انجام دهند (مانند تولید یک تصویر از روی یک توصیف متنی).
نتیجهگیری
شبکه عصبی پردازش تصویر از یک موضوع تحقیقاتی صرف به یک ابزار قدرتمند و فراگیر تبدیل شده است که شیوه تعامل ما با جهان دیجیتال و فیزیکی را بازتعریف میکند. از درک مبانی لایههای کانولوشن گرفته تا کاوش در معماریهای تاریخی و کاربردهای متحولکننده، این فناوری نشاندهنده قدرت یادگیری ماشین در حل مسائل پیچیدهای است که زمانی غیرقابل حل به نظر میرسیدند.
آینده این حوزه نهتنها در بهبود دقت مدلها، بلکه در دموکراتیک کردن دسترسی به آنها، افزایش تفسیرپذیری و ترکیب آنها با سایر حوزههای هوش مصنوعی نهفته است. این سفر تازه آغاز شده است و بدون شک شاهد نوآوریهای بیشتری خواهیم بود که مرزهای بین توانایی انسان و ماشین را جابجا خواهد کرد.





