شناسایی نوری کاراکتر (OCR) کارآمد برای بوردهای چیپ و آیسی: اطمینان از رهگیری قابل اعتماد در تولید نیمههادی

در دنیای پویا و رو به پیشرفت تولید نیمههادی، اطمینان از شناسایی دقیق و رهگیری بوردهای چیپ و آیسی از اهمیت بالایی برخوردار است. با افزایش سرعت خطوط تولید و بالاتر رفتن استانداردهای کیفیت، روشهای…
در دنیای پویا و رو به پیشرفت تولید نیمههادی، اطمینان از شناسایی دقیق و رهگیری بوردهای چیپ و آیسی از اهمیت بالایی برخوردار است. با افزایش سرعت خطوط تولید و بالاتر رفتن استانداردهای کیفیت، روشهای سنتی خواندن و رهگیری شناسههای سینیها ناکارآمد میشوند. کنتراست پایین نشانهها، کاراکترهای برجسته، فاصلههای متغیر و شرایط نوری نامناسب میتوانند عملکرد سیستمهای OCR سنتی را به خطر بیندازند و منجر به خطا در خواندن، تأخیر در تولید و حتی فراخوانهای پرهزینه شوند. در این مقاله، بهصورت جامع به چالشهای مخصو÷ص OCR روی بوردهای چیپ و آیسی میپردازیم، نحوهٔ غلبه بر این مشکلات با استفاده از سختافزار و نرمافزار پیشرفته را بررسی میکنیم و راهنمای عملی برای پیادهسازی یک سیستم OCR مبتنی بر هوش مصنوعی قابل اعتماد را با تمرکز ویژه بر اکوسیستم pylon vTools شرکت Basler ارائه میدهیم. پس از مطالعهٔ این مقاله، درک روشنی از نحوهٔ پیادهسازی یک جریان کاری OCR خواهید داشت که بتواند کاراکترهای دشوار روی بوردهای چیپ و آیسی را با اطمینان بالا شناسایی کند و یکپارچگی تولید و رهگیری را تضمین نماید
چرا بوردهای چیپ به OCR مبتنی بر هوش مصنوعی نیاز دارند
در تولید نیمههادی، هر جزء—از دای (Die) خام گرفته تا دستگاه بستهشده—باید به دقت ردیابی شود. روند تولید از برش ویفر (Wafer Dicing) تا چسباندن دای (Die Attach)، قالبگیری (Molding)، تست و بستهبندی نهایی شامل مراحل متعددی است که در هر مرحله دادههایی باید به دای یا مجموعهای از دایها اختصاص یابد. بوردهای چیپ و آیسی نقش کلیدی در این فرآیند ایفا میکنند. آنها دایهای جداشده از ویفر، دایهای تستشده، دستگاههای بستهبندیشده و حتی زیرمجموعهها را بین مراحل مختلف حمل میکنند.
روشهای سنتی شامل خواندن دستی لیبلها یا استفاده از بارکدهایی است که به سینیها الصاق میشوند. با این حال، در محیطهایی که نیاز به سرعت بالا و دقت دارد، ورود دستی دادهها زمانبر شده و باعث تأخیر، خطای انسانی و اشتباه در برچسبگذاری میشود. بارکدها نیز ممکن است در معرض سایش مکانیکی یا مواد شیمیایی قرار بگیرند یا در دمای بالای خطوط تولید صنعتی جدا شوند. افزون بر این، برخی سینیها دارای کاراکترهای برجسته حکشده یا قالبزده (Embedded) هستند و برای آنها نمیتوان از بارکد استفاده کرد.
OCR به صورت غیرتماسی و خودکار امکان خواندن مستقیم شناسههای متنی را از سطح سینی فراهم میکند. با پیادهسازی یک سیستم OCR در نقاط کلیدی خط تولید—نظیر بعد از برش ویفر، بعد از دستهبندی تست و قبل از بستهبندی—کارخانهها میتوانند رهگیری end-to-end را حفظ کنند. این کار اطمینان میدهد که اگر نقصی در مرحله بعدی ظاهر شود، منشا آن به یک ویفر مشخص، ایستگاه تست یا دسته تولید قابل پیگیری است. تشخیص دقیق بوردهای چیپ از ایجاد اشتباهات در جابجایی، تضمین ردگیری و حفظ یکپارچگی تولید جلوگیری میکند و از زمان توقف، فراخوان و مسائل نظارتی جلوگیری مینماید.
چالشهای کلیدی در OCR مبتنی بر هوش مصنوعی برای بوردهای چیپ و آیسی
پیادهسازی OCR روی بوردهای چیپ و آیسی کار آسانی نیست. برخلاف خواندن یک برچسب چاپی روی کاغذ سفید که کنتراست بالا و کاراکترهای کاملاً تعریفشدهای دارد، بوردهای چیپ مجموعهای از چالشهای منحصر به فرد را ارائه میدهند. در ادامه بر موانع اصلی و دلیل دشواری هر یک تأکید میکنیم.
۱. کنتراست پایین کاراکترهای برجسته
بسیاری از بوردهای چیپ از پلاستیک قالبریزیشده یا فلز ساخته میشوند و کاراکترها (اعداد، حروف یا کدها) به صورت کمی برجسته نسبت به پسزمینه حک یا قالبزده شدهاند. تفاوت بازتابش (Reflectivity) بین کاراکتر برجسته و سطح اطراف آن ممکن است حداقل باشد. تحت شرایط نوری معمولی در کارخانه—نور کم، نور غیرمستقیم، یا نور فلورسنت—این کاراکترها ممکن است بهصورت سایههای کمرنگ مشاهده شوند. الگوریتمهای OCR سنتی که بر مبنای آستانهگذاری (Thresholding) یا تطبیق الگو (Template Matching) عمل میکنند، اغلب قادر به تمایز این تفاوت کم نوردهی نیستند.
بهعنوان مثال، سینی با کدی مانند “A1234” که روی سطح پلاستیکی خاکستری بهصورت برجسته حک شده است را در نظر بگیرید. در نور کم یک کارخانه و با نور فلورسنت، آن کد ممکن است تنها بهصورت یک برجستگی کمرنگ ظاهر شود و اختلاف سطح بین جسم و پسزمینه بهسختی قابل تشخیص باشد. الگوریتم OCR سنتی ممکن است تنها یک ناحیه خاکستری یکنواخت ببیند و لبههای کاراکتر را تشخیص ندهد. این مشکل با سایش سطح—پیدا شدن خراش، لکهگیریهای مواد شیمیایی یا گردوغبار—بدتر میشود و کنتراست را بیشتر کاهش میدهد.
۲. فاصلههای کاری متغیر و مشکلات فوکوس
همانطور که خودرانها یا بازوهای رباتیک سینیها را جابجا میکنند، موقعیت آنها نسبت به سنسور بینایی (Vision Sensor) ممکن است کمی متغیر باشد. اختلاف چند میلیمتری در فاصله موجب میشود در صورت عمق میدان (Depth of Field) ناکافی، تصویر خارج از فوکوس شود. با کمکردن دیافراگم برای افزایش عمق میدان، نور دریافتی کاهش یافته و مشکل کنتراست را تشدید میکند. از طرف دیگر، باز نگهداشتن دیافراگم برای جمعآوری نور بیشتر عمق میدان را کم میکند و نیاز به فوکوس دقیقتر را افزایش میدهد.
در خطوط تولید با سرعت بالا، زمان کافی برای قرارگیری دقیق هر سینی در موقعیت ثابت وجود ندارد. در عوض، سیستم بینایی باید تغییرات ارتفاع ناشی از انباشتهشدن سینیها، مداخله اپراتور یا ارتعاش نقاله را تحمل کند. فوکوس نامناسب منجر به تار شدن کاراکترها، از بین رفتن لبهها و در نهایت عملکرد ناپایدار OCR میشود.
۳. نورپردازی نامناسب و بازتابهای ناخواسته
نورپردازی مناسب اساس هر پیادهسازی موفق OCR است. با این حال، سالنهای کارخانه معمولاً دارای نورپردازی ناهمگن هستند: چراغهای فلورسنت سقفی، بازتاب نور از سطوح فلزی، نور خورشید پراکنده از پنجرهها و تغییرات ناگهانی زمانی که ماشینها خاموش و روشن میشوند. این تغییرات میتواند سایههای غیرقابلپیشبینی روی کاراکترهای برجسته بیاندازد یا نقاط درخشان (Specular Highlights) ایجاد کند که قسمتهایی از کد را بشویند.
برای بوردهای فلزی یا با پوشش براق (مثلاً آلومینیوم یا استیل صیقلی)، نور مستقیم میتواند بازتابهای شدیدی ایجاد کند که نقاط روشن را در تصویر تشکیل داده و بخشهایی از کد را غیرقابلتشخیص میکند. از طرفی نور کم در نواحی سایهدار باعث تاریکی بیشازحد (Underexposure) میشود. هر دو حالت برای OCR مضر هستند، زیرا این الگوریتمها به کنتراست پایدار بین تیرگی و روشنی کاراکتر وابستهاند.
۴. نیاز به سرعت بالا در خطوط تولید
کارخانههای نیمههادی و مراکز مونتاژ/تست اغلب به چرخههای زمانی در حد چند ثانیه—و گاهی کسری از ثانیه—برای هر دسته محصولات نیاز دارند. اگر سیستم OCR برای تشخیص کد سینی چند بار تلاش کند یا برای هر خواندن مدت زمان زیادی صرف شود، این تأخیر میتواند بهصورت تصاعدی در کل خط تأثیر منفی بگذارد و زمان چرخهها (Cycle Time) و بهرهوری تجهیزات (OEE) را کاهش دهد. برای مثال، اگر یک خواندن ناموفق باعث آلارم یا نیاز به مداخله دستی شود، خط تولید ممکن است متوقف شده و اپراتور باید موقعیت سینی را تصحیح کند یا کد را بهصورت دستی وارد نماید—که منجر به توقفهای پرهزینه میشود.
بنابراین، راهکار OCR باید در حد امکان سریع باشد، بتواند به خطاها واکنش آنی نشان دهد و از ابتدا با یک خواندن درست کاراکترها را شناسایی کند. زمانهای چند صد میلیثانیه یا بیشتر، شانس تأخیر را بهطور چشمگیری افزایش میدهد. یک سیستم OCR مؤثر باید نرخ خواندن بسیار بالا (> ۹۹.۹٪) را تحت سرعتهای خط (Line Speeds) داشته باشد—که معمولاً به کمتر از ۱–۲ ثانیه برای هر انتقال سینی نیاز دارد.
اجزای یک راهکار OCR مبتنی بر هوش مصنوعی جامع برای بوردهای چیپ
با در نظر گرفتن چالشهای فوق، یک راهکار جامع OCR برای بوردهای چیپ و آیسی باید ترکیبی از سختافزار پیشرفته، نرمافزار قدرتمند و جریان کاری هوشمند باشد. در ادامه بوردهای اصلی این قطعات را بررسی میکنیم:
۱. ملاحظات سختافزاری
-
انتخاب دوربین
-
رزولوشن و اندازه حسگر: دوربینی با رزولوشن کافی برای تفکیک فونتهای کوچک (اغلب ۶–۸ پوینت یا کمتر) که روی سینی قرار دارد، ضروری است. حسگر شاتر جهانی (Global Shutter) برای جلوگیری از تاری ناشی از حرکت (Motion Blur) در سرعتهای بالا مناسب است.
-
نرخ فریم: برای همگامسازی با نقاله یا بازوی رباتیک سریع، دوربینی که بتواند ۶۰–۱۲۰ فریم بر ثانیه (fps) ضبط کند، شانس بیشتری دارد که حداقل یک فریم شارپ در لحظهٔ مناسب ضبط کند.
-
-
لنز و میدان دید (FoV)
-
لنز ماکرو: چون کاراکترهای روی سینی کوچک هستند (معمولاً در حد چند میلیمتر)، لنز ماکرو با فاصلهٔ فوکوس حداقل کوتاه بسیار مفید است.
-
فوکوس قابل تنظیم یا خودکار: لنزهای دارای کنترل فوکوس موتورایز برای فواصل متفاوت بهسادگی ادغام میشوند و از فوکوس دستی بینیاز میکنند.
-
-
نورپردازی
-
نورپردازی همگن و با شدت بالا: نورهای LED حلقهای (Ring Light) یا بکلایتها با دیفیوزر میتوانند روشنایی یکنواختی ایجاد کنند که برجستگی کاراکتر را با سایه و هایلایت دقیقتر نشان میدهد.
-
فیلترهای پلاریزه (Polarizers): برای سطوح بازتابدهنده، فیلترهای پلاریزه روی منابع نور و لنز دوربین میتوانند از بازتابهای ناخواسته جلوگیری کرده و کنتراست را بهبود دهند.
-
نورپردازی میدان تاریک (Darkfield): برای کاراکترهای برجسته با کنتراست پایین، نورپردازی میدان تاریک—که نور از زوایای کم (نزدیک موازی با سطح) تابیده میشود—میتواند سایههای بلند ایجاد کند و برجستگی کاراکترها را بهتر نمایان سازد.
-
-
محفظه و محافظت محیطی
-
قاب صنعتی: دوربین و نورها باید در محفظههای صنعتی با درجه حفاظت IP65 یا بالاتر نصب شوند تا در برابر گردوغبار، لرزش و تغییرات دما در محیطهای تولیدی محافظت شوند.
-
محافظ لنز: لنزها باید با پوششهای قابل تمیزکاری محافظت شوند تا از تجمع گردوغبار یا روغنهای صنعتی جلوگیری شود.
-
-
اتوماسیون و موقعیتیابی
-
مکانیسم تحریک (Triggering): سنسورهای فوتوالکتریک (Photoelectric) یا خروجی انکدر (Encoder) از نقاله میتوانند دوربین را در لحظهای که سینی به میدان دید نزدیک میشود، تحریک کنند.
-
راهنماهای مکانیکی: راهنماهای فیزیکی (ریل یا گارد) میتوانند موقعیت سینی را در یک صفحه ثابت نگه دارند و تغییرات فاصله و زاویه را به حداقل برسانند؛ با این حال، حتی با راهنما نیز انحرافهای جزئی گریزناپذیرند—بنابراین فوکوس خودکار یا عمق میدان بزرگ ضروری باقی میماند.
-
۲. قطعات نرمافزاری
-
اکتساب تصویر و پیشپردازش
-
تنظیم خودکار نوردهی و بهره (Auto-Exposure و Auto-Gain): دوربینها باید طوری تنظیم شوند که خودکار نوردهی (Exposure) و بهره (Gain) را با تغییرات نوری تنظیم کنند تا از نوردهی بیشازحد یا کمنور جلوگیری شود.
-
فیلترهای کاهش نویز: الگوریتمهای نویزگیری (مثلاً فیلتر میانگینگیر یا Median) میتوانند نویز حسگر را کاهش دهند که ممکن است با کاراکتر اشتباه گرفته شود.
-
افزایش کنتراست: تکنیکهایی مانند برابرسازی هیستوگرام (Histogram Equalization) یا آستانهگذاری تطبیقی (Adaptive Thresholding) میتوانند تفاوتهای کم نوردهی بین کاراکترهای برجسته و پسزمینه را تقویت کنند.
-
-
موتور OCR مبتنی بر هوش مصنوعی
-
OCR سنتی (pylon vTool OCR): ابزار OCR شرکت Basler در نرمافزار pylon به منظور کاربردهای صنعتی طراحی شده و با حداقل تنظیمات میتواند متون استاندارد و با موقعیت ثابت را تشخیص دهد.
-
OCR مبتنی بر هوش مصنوعی: برای ناحیههای متنی پیچیده—جایی که موقعیتهای مختلف، کاراکترهای تحریفشده یا پسزمینههای شلوغ وجود دارد—یک موتور OCR مبتنی بر هوش مصنوعی (عموماً مبتنی بر شبکههای عصبی کانولوشن (CNN) یا شبکههای بازگشتی (RNN)) دقت بهمراتب بالاتری ارائه میدهد. این مدلها با مجموعه دادههای بزرگ آموزشدیدهاند که شامل فونتها، جهتها و شرایط نوری متنوع است و میتوانند در شرایط دشوار متن را با اطمینان بخوانند.
-
-
فشردهسازی کاراکتر و استخراج ROI (Region of Interest)
-
تطبیق الگو یا تشخیص ویژگی: قبل از اعمال OCR، نرمافزار باید ناحیه حساس به متن (ROI) را پیدا کند (مثلاً جایگاهی که کد سینی برجسته شده). این کار میتواند از طریق تطبیق شکل (مثل شناسایی محیط مستطیلی که کاراکترها در آن قرار دارد) یا تشخیص ویژگیهای پیشرفته (یافتن ناحیه بر اساس نشانههای بصری خاص روی سینی) انجام شود.
-
اصلاح پرسپکتیو (Perspective Correction): اگر سینی کمی کج یا چرخیده باشد، الگوریتمهای همولوگرافی میتوانند ROI را طوری اصلاح کنند که کاراکترها رو به دوربین قرار بگیرند و OCR دقیقتر انجام شود.
-
-
پسپردازش و اعتبارسنجی
-
بررسی الگوی متن یا فرمت کد: بسیاری از کدهای سینی از فرمتی استاندارد پیروی میکنند (مثلاً یک حرف و چهار رقم). نرمافزار میتواند نتایج OCR را بر اساس الگوی انتظار اعتبارسنجی کند و خواندههای ناسازگار را نادیده بگیرد.
-
بررسی افزونگی: ثبت چند فریم و مقایسه نتایج OCR در فریمهای پیاپی میتواند خطاهای کاذب را کاهش دهد. اگر دو خواندن پیاپی مطابقت داشت، سیستم میتواند کد را با اطمینان بپذیرد.
-
جستجوی پایگاه داده و تأیید: پس از OCR، کد شناسایی شده میتواند با یک پایگاه داده مرکزی مطابقت داده شود تا خواندههای غیرمنتظره یا نادرست شناسایی شود.
-
۳. یکپارچهسازی سیستم و جریان کاری
یک سیستم OCR موفق بوردهای چیپ تنها به سختافزار و نرمافزار منتهی نمیشود؛ بلکه نحوهٔ هماهنگی این اجزا در چارچوب گستردهتر سیستم اجرای تولید (MES) نیز اهمیت دارد. در ادامه چند ملاحظه کلیدی برای یکپارچهسازی آورده شده است:
-
انتقال داده در زمان واقعی
-
GigE Vision یا USB3 Vision: دوربینهای صنعتی مدرن تصویر را از طریق اترنت گیگابیتی یا USB3 منتقل میکنند. یک کامپیوتر صنعتی (IPC) که نرمافزار pylon را اجرا میکند، این فریمها را با سرعت بالا دریافت میکند.
-
پروتکلهای صنعتی: کد شناسایی شده باید به سیستمهای پاییندستی—مانند کنترلرهای سلول رباتیک، PLC یا MES—از طریق پروتکلهای استاندارد صنعتی مانند Ethernet/IP، PROFINET یا OPC UA ارسال شود.
-
-
تحریک و همگامسازی
-
تحریک مبتنی بر سنسور: سنسورها لبهٔ جلویی سینی را تشخیص داده و پالس تحریک را به دوربین میفرستند. دوربین یک تصویر میگیرد، چراغها را همگامسازی میکند و فریم را به کامپیوتر پردازش ارسال میکند.
-
تحریک زمانبندیشده: در سیستمهای نقالهای بدون سنسور فیزیکی، میتوان از تحریک زمانبندیشده استفاده کرد؛ البته این روش نسبت به تحریک مبتنی بر سنسور کمتر مقاوم است و در صورت تغییر سرعت کمربند ممکن است فریمهای تار یا از دست رفته ایجاد شود.
-
-
پردازش در لبه (Edge) در مقابل پردازش متمرکز
-
پردازش درون دوربینی: برخی دوربینهای هوشمند امکانات پردازش (CPU یا FPGA داخلی) دارند و میتوانند الگوریتمهای OCR را مستقیماً روی دوربین اجرا کنند. این روش نیاز به کامپیوتر جداگانه را حذف کرده و تاخیر را کاهش میدهد، اما ممکن است محدودیتهایی برای پیادهسازی OCRهای مبتنی بر هوش مصنوعی پیشرفته داشته باشد.
-
پردازش متمرکز روی کامپیوتر صنعتی: یک کامپیوتر صنعتی اختصاصی (IPC) که نرمافزار pylon vTools را اجرا میکند، میتواند چندین دوربین را بهطور همزمان پردازش کند، پیشپردازش، استنتاج هوش مصنوعی و تعامل با پایگاه دادهها را انجام دهد. این روش مرکزی انعطافپذیری و مقیاسپذیری بالاتری فراهم میکند، بهویژه زمانی که از OCR مبتنی بر هوش مصنوعی استفاده شود.
-
-
کنترل خطا و اطلاعرسانی به اپراتور
-
منطق دستهبندی و رد (Binning و Reject): اگر خواندن سینی ناموفق باشد یا کد شناسایی شده غیرمنتظره باشد، سیستم میتواند سینی را به یک مسیر بازرسی هدایت کند یا پیام هشدار به ایستگاه اپراتور ارسال کند.
-
رابط کاربری گرافیکی (GUI): نمایش زندهٔ تصویر دوربین، متن شناسایی شده، نمرهٔ اطمینان (Confidence) و هر فریم مردود (Rejected) میتواند به تکنسینها کمک کند تا به سرعت مشکلات را تشخیص دهند. مثلاً اگر موتور OCR مکرراً سینی خاصی را اشتباه میخواند، اپراتور میتواند نورپردازی یا فوکوس لنز را بلافاصله تنظیم کند.
-

بهینهسازی اکتساب تصویر: نورپردازی و فوکوس
ضربالمثل “اگر ورودی نامناسب باشد، خروجی نیز نامناسب خواهد بود” خصوصاً در کاربردهای OCR صادق است. حتی بهترین موتور OCR نمیتواند از تصویری که تار یا با ناهمخوانی نوردهی گرفته شده است، اطلاعات دقیق استخراج کند. بنابراین بهینهسازی اکتساب تصویر مرحلهای غیرقابلچشمپوشی است. در زمینهٔ OCR بوردهای چیپ، دو فاکتور نورپردازی و فوکوس اهمیت ویژهای دارند.
۱. استراتژیهای نورپردازی حرفهای
-
نورپردازی زمینه تار (Darkfield) در مقابل نورپردازی زمینه روشن (Brightfield)
-
Brightfield: نور بهصورت عمود بر سطح سینی تابیده میشود. اگر کاراکترها با جوهر چاپ شده یا حکشده باشند، این روش مناسب است، ولی برای کاراکترهای برجسته روی سطوح مات مؤثر نیست.
-
Darkfield: نور از زاویههای کم—نزدیک به موازی با سطح سینی—تابیده میشود و لبههای برجسته سایههای بلندی ایجاد میکنند که در تصویر ثبت میشود. این کار کنتراست کاراکترها را بهطور چشمگیری افزایش میدهد. در عمل، حلقهٔ نور (Ring Light) نصبشده دور لنز در زاویه کم یا یک سیستم فیبر نوری با پرتوهای قابل تنظیم میتواند چنین اثری ایجاد کند.
-
-
نورپردازی پخششده (Diffused) در مقابل نور مستقیم (Direct)
-
نورپردازی پخششده: استفاده از دیفیوزر (صفحات اکریلیک مات یا صفحهٔ پلکسیگلس مات) باعث پخش یکنواخت نور روی سینی میشود و از سایهها و نقاط برّاق شدید جلوگیری میکند. این روش برای سطوح نیمهمنعکس یا با بافت (Texture) مفید است.
-
نور مستقیم استروب (Strobe): برای نقالههای بسیار سریع، میتوان از استروب LED با شدت بالا استفاده کرد که با اکسپوژر دوربین همگامسازی شده و حرکت را منجمد میکند. با این حال، نور استروب باید اندکی پخششده باشد تا از ایجاد نقاط بازتابشی که سنسور دوربین را اشباع میکنند جلوگیری شود.
-
-
پلاریزه کردن (Polarization)
بسیاری از مواد سینی—بهویژه فلز یا پلاستیکهای براق—بازتابهای شدید (Specular Reflections) تولید میکنند که لبههای کاراکتر را پنهان میکند. با نصب فیلتر پلاریزه روی منبع نور و فیلتر پلاریزه عمود بر آن روی لنز دوربین (Cross-Polarization)، میتوان بازتابهای ناخواسته را بهطور قابلتوجهی کاهش داد و کنتراست کاراکترها را بهبود بخشید. -
دمای رنگ و طول موج
-
LED سفید در مقابل نور تکرنگ (Monochromatic): LED سفید برای استفاده عمومی مناسب است، اما نور تکرنگ (مثلاً LED قرمز یا آبی) میتواند کنتراست را با توجه به بازتابشهای طیفی سطح سینی بهبود دهد. اگر سینی نور قرمز را بیشتر از کاراکتر جذب کند، LED قرمز باعث میشود کاراکترها تاریکتر و پسزمینه روشنتر به نظر برسند.
-
دمای رنگ قابل تنظیم: برخی راهکارهای صنعتی امکان تنظیم دمای رنگ (مثلاً از ۳۰۰۰K تا ۶۵۰۰K) را فراهم میکنند تا با شرایط محیطی سازگار شوند و از رنگهای ناخواسته (Color Cast) که ممکن است تعادل رنگ سفید دوربین را تحت تأثیر قرار دهد، جلوگیری کنند.
-
۲. فوکوس خودکار دروندوربینی برای فواصل متغیر
متمرکز نگه داشتن فوکوس روی کاراکترهای برجستهٔ سینی هنگامی که فاصله کار ثابت نیست، کار چالشبرانگیزی است. تنظیم دستی فوکوس با استفاده از عمق میدان زیاد (با دیافراگم بستهتر) ممکن است به نورپردازی قویتر نیاز داشته باشد و اثر تفرق (Diffraction) میتواند وضوح تصویر را تا حدی کاهش دهد.
راه حل مؤثر استفاده از فناوری فوکوس خودکار دروندوربینی (In-Camera Autofocus) شرکت Basler است که بهصورت زیر عمل میکند:
-
فوکوس مبتنی بر کنتراست (Contrast-Based AF)
-
دوربین به طور مداوم فریمهای زنده را تحلیل میکند و مقدار کنتراست یک ناحیهٔ از پیش تعریفشده (معمولاً ناحیهای که کد سینی در آن قرار دارد) را اندازهگیری میکند. با نزدیک یا دور شدن سینی، الگوریتم AF فاصله زوم لنز را تغییر میدهد تا بیشترین کنتراست ممکن در ROI بهدست آید.
-
این روش برای بوردهایی که بهصورت ثابت یا با حرکت آهسته طی میشوند مناسب است. الگوریتم AF حجم جستجوی فوکوس را در محدودهای از فواصل امتحان میکند و به کمابیش با بیشینه کردن کنتراست به بهترین فوکوس میرسد.
-
-
فوکوس پیشبینیشده (Predictive AF) با سنسور فاصله
-
برای کاربردهای بسیار پرسرعت که نیاز به تنظیم فوکوس در میلیثانیه دارند، گاهی از سنسور فاصلهیابی (Time-of-Flight یا لیزر تری انگولیشن) جداگانه استفاده میشود. این سنسور فاصلهٔ سینی تا دوربین را اندازه میگیرد و به موتور فوکوس لنز فرمان میدهد تا قبل از ثبت تصویر به سمت صفحهٔ فوکوس مناسب برود.
-
سپس دوربین پس از دریافت تحریک (Trigger)، فوکوس را به صورت جزئی تنظیم میکند تا اطمینان حاصل شود که فریم نهایی کاملاً شارپ ثبت میشود.
-
-
مزایای فوکوس خودکار
-
شارپی مداوم: بدون توجه به تغییرات جزئی ارتفاع سینی به خاطر انباشته شدن یا لرزش نقاله، کاراکترها همیشه شارپ باقی میمانند.
-
کاهش پیچیدگی سیستم: نیازی به لنزهای تلهسنتریک گرانقیمت یا ابزارهای مکانیکی پیچیده برای ثابت نگهداشتن فاصله نیست.
-
راهاندازی و کالیبراسیون سریعتر: به جای تنظیم دستی فوکوس برای هر سبک جدید سینی، AF به صورت خودکار نقطهٔ فوکوس بهینه را پیدا میکند و ساعتها زمان مهندسین را ذخیره میکند.
-
نکته: هنگام پیادهسازی فوکوس خودکار، ضروری است که یک ناحیهٔ فوکوس (ROI) قابل اعتماد برای جستجوی کنتراست تعریف شود. اگر ROI بیش از حد کوچک یا نادرست باشد، الگوریتم AF روی بافتهای نامربوط (مثلاً سطح ناقص سینی) جستجو میکند و بهجای کاراکتر به لبههای تصادفی فوکوس میکند. تعریف یک ROI کمی بزرگتر که شامل کل بلوک متن برجسته باشد، معمولاً بهترین نتیجه را میدهد.

پیادهسازی OCR مبتنی بر هوش مصنوعی با pylon vTool OCR شرکت Basler
بعد از بهینهسازی اکتساب تصویر، گام بعدی ادغام یک موتور OCR قدرتمند است. ابزار pylon vTool OCR شرکت Basler برای کاربردهای صنعتی طراحی شده و مزایای زیادی نسبت به کتابخانههای عمومی OCR ارائه میدهد. در این بخش، دلایل برتری pylon vTool OCR برای بوردهایی چیپ را بررسی میکنیم و نحوهٔ استفاده از آن را بهطور گامبهگام بیان میکنیم.
۱. معرفی pylon vTools
مجموعهٔ نرمافزاری pylon شرکت Basler شامل مجموعهای از ابزارهای بینایی (Vision Tools یا vTools) است که برای انجام وظایف مختلف پیشپردازش، تحلیل و پردازش تصویر طراحی شدهاند. در میان آنها، vTool OCR بهطور خاص برای شناسایی کاراکتر در محیطهای صنعتی بهینه شده است. ویژگیهای کلیدی عبارتاند از:
-
طراحی دستورالعمل (Recipe) بصری با کشیدن و رها کردن: کاربران میتوانند یک “دستورالعمل” (Recipe) OCR را با کشیدن بلوکهای از پیش تعریفشده—ورودی تصویر، پیشپردازش، جداسازی کاراکتر، OCR و پسپردازش—روی یک بوم (Canvas) بصری بچینند. نیازی به برنامهنویسی نیست و این روش برای مهندسین بینایی با دانش محدود کدنویسی مناسب است.
-
پشتیبانی از زبانهای متعدد: vTool OCR میتواند کاراکترهای اسکویی (Latin)، سیریلیک (Cyrillic)، کانجی (Kanji) و زبانهای دیگر را شناسایی کند که برای کاربردهای جهانی در سایتهای تولیدی مختلف مفید است.
-
پارامتربندی و تنظیم دقیق: هر بلوک در دستورالعمل پارامترهایی مانند آستانههای پیشپردازش، محدودهٔ ارتفاع کاراکتر، مجموعهٔ کاراکترهای مجاز و … را در اختیار کاربر میگذارد که میتواند برای سبک فونت و نشانه مخصوص سینی تنظیم شود.
-
عملکرد با سرعت بالا: پیادهسازی بهینهشدهٔ زبان C++ زیرساخت vTools زمان اجرای OCR را به زیر ۱۰۰ میلیثانیه در هر ROI محدود کرده که از عهدهٔ سرعتهای خطوط تولید برمیآید.
-
ادغام آسان با SDK pylon: برای کاربران پیشرفته که تمایل به برنامهنویسی در C++، C# یا Python دارند، SDK pylon رابطهایی را برای ادغام vTool OCR در برنامههای سفارشی فراهم میکند و انعطافپذیری فراتر از بوم بصری را امکانپذیر میسازد.
-
ابزارهای آزمایش و اعتبارسنجی داخلی: نرمافزار شامل ماژولهایی برای آزمایش عملکرد OCR روی تصاویر نمونه، محاسبهٔ معیارهای دقت (Read Rate)، نرخ خطا (False Positive Rate) و مشاهدهٔ نمونههای ناموفق برای رفع اشکال سریعتر است.
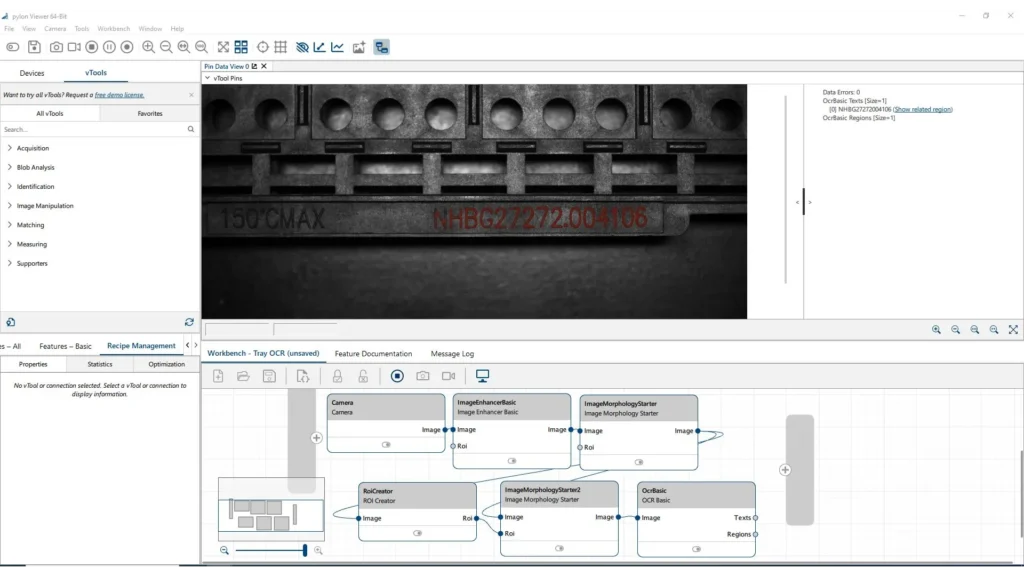
۲. ایجاد دستورالعمل (Recipe) با کشیدن و رها کردن
یکی از مزایای برجستهٔ pylon vTool OCR، سهولت استفاده آن است. در ادامه یک راهنمای گامبهگام برای ایجاد دستورالعمل OCR برای بوردهای چیپ ارائه شده است:
-
شروع یک دستورالعمل جدید
-
pylon Viewer را باز کنید و طراح دستورالعمل vTool را اجرا کنید. یک دستورالعمل جدید برای OCR بسازید و نام مناسبی مانند “ChipTray_OCR_Recipe” به آن اختصاص دهید.
-
-
افزودن بلوک ورودی تصویر
-
بلوک “Camera” یا “Image File” را روی بوم بکشید. اگر از دوربین Basler استفاده میکنید، مدل دوربین را انتخاب کرده و پارامترهای اکتساب (رزولوشن، نوردهی، بهره) را تنظیم کنید.
-
اگر در حالت آزمایش آفلاین هستید، تصاویر نمونهٔ بوردهای چیپ را که تحت شرایط نوری واقعی گرفتهاید، بارگذاری کنید.
-
-
تعریف ROI (Region of Interest)
-
بلوک “ROI” را اضافه کنید تا محل تقریبی کد سینی را در تصویر مشخص کنید. با استفاده از پنجرهٔ پیشنمایش، یک مستطیل پیرامون کاراکترهای برجستهٔ سینی بکشید. این کار سرعت پردازش را بالا برده و تشخیص ناحیههای اشتباه را کاهش میدهد.
-
-
بلوک پیشپردازش
-
بلوک “Preprocessing” را برای عملیاتی مانند تبدیل به خاکستری (Grayscale)، فیلتر کاهش نویز (مثلاً Median Filter)، افزایش کنتراست (مثلاً برابرسازی هیستوگرام تطبیقی) و آستانهگذاری باینری (Binarization) اضافه کنید.
-
مقادیر آستانه را تنظیم کنید: با توجه به کنتراست کم، از آستانهگذاری تطبیقی با اندازه بلوک کوچک استفاده کنید تا تفاوتهای گنگ محلی شناسایی شوند.
-
اگر فیلتر پلاریزه یا نور خاصی باعث شد که یک کانال رنگی خاص (مثلاً کانال قرمز) کنتراست بهتری بدهد، پیشپردازش را طوری تنظیم کنید که آن کانال استخراج شود.
-
-
جداسازی کاراکتر (Character Segmentation)
-
از بلوک “Blob Analysis” یا “Connected Components” برای جداسازی نواحی بالقوهٔ کاراکتر استفاده کنید. پارامترهای حداقل و حداکثر اندازهٔ Blob را با توجه به ابعاد پیکسل انتظارشده برای کاراکترها (مثلاً عرض ۱۰–۳۰ پیکسل، ارتفاع ۱۵–۳۰ پیکسل) تنظیم کنید.
-
فیلترهای شکلی (Shape Filters) را برای حذف Blobهای بیارتباط (مثلاً خراشهای تصادفی یا نقصهای سطح پلاستیک) تنظیم کنید. از معیارهایی مانند بیضیبودن (Circularity) یا نسبت ابعاد (Aspect Ratio) استفاده کنید تا فقط اشکالی که شبیه حروف و اعداد هستند، باقی بمانند.
-
-
بلوک OCR
-
بلوک “OCR Engine” را روی بوم بکشید. مجموعهٔ کاراکترهای مجاز—اغلب حروف بزرگ انگلیسی (A–Z) و ارقام (0–9)—را مشخص کنید تا موتور تنها به دنبال نمادهای معتبر بگردد و خطاهای کاذب کاهش یابد.
-
پارامترهایی مانند حداقل ارتفاع کاراکتر، حداکثر زاویهٔ چرخش (اگر سینی ممکن است کمی بچرخد) و حداکثر فاصلهٔ بین کاراکترها (برای گروهبندی به رشتهها) را تنظیم کنید.
-
الگوی فرمت کد مورد انتظار را تعیین کنید (مثلاً “[A-Z]{1}[0-9]{4}”) تا در پسپردازش خواندههای نامطابق رد شوند.
-
-
پسپردازش و اعتبارسنجی
-
بلوک “Validation” را اضافه کنید تا خروجی OCR را با یک عبارت باقاعده (Regex) بررسی کند. اگر خواندهها با الگو مطابقت نداشتند، پرچم خطا زده و تلاش مجدد یا اخطار به اپراتور ارسال شود.
-
اختیاری: اگر کد سینی شامل رقم کنترلی (Check Digit) باشد، صحت هر خوانده با محاسبهٔ چکدیجیت بررسی شود.
-
-
پیکربندی خروجی
-
مشخص کنید که کد شناسایی شده چگونه خروجی شود:
-
فایل متنی یا CSV: برای ثبت خواندهها و زمانسنجی.
-
I/O دیجیتال یا فرمان شبکه: ارسال سیگنال “پاس/فیل” به تجهیزات پاییندستی.
-
ادغام با MES: استفاده از رابط اسکریپتنویسی pylon یا میانافزار خارجی (مثلاً MQTT، OPC UA) برای ارسال مستقیم کد به پایگاه دادهٔ MES.
-
-
-
آزمایش و رفع اشکال
-
دستورالعمل را روی مجموعهای از تصاویر نمونه اجرا کنید و نتایج OCR را همراه با پیشنمایش روی تصویر مشاهده کنید. هر خواندهٔ اشتباه یا از دسترفته را ثبت کنید.
-
پارامترهای پیشپردازش، فیلترهای اندازهٔ Blob یا موقعیت ROI را تنظیم کنید تا نرخ خواندن روی مجموعهٔ متنوعی از نمونهها به حد مطلوب (مثلاً بالای ۹۹.۹٪) برسد.
-
از آنجا که طراح دستورالعمل pylon vTool OCR بصری است، مهندسین میتوانند تأثیر هر بلوک را در زمان واقعی مشاهده کرده و زمان توسعه را نسبت به کدنویسی از ابتدا بهشکل چشمگیری کاهش دهند.
۳. پیکربندی و تنظیم OCR
دستیابی به نرخ خواندن بالا (> ۹۹.۹٪) روی بوردهای چیپ معمولاً نیازمند تنظیمات دقیق و چندباره است. در ادامه چند راهنمای عملی آورده شده است:
-
محدودهٔ ارتفاع و عرض کاراکتر
-
ابعاد متوسط کاراکتر سینی را بر حسب پیکسل در رزولوشن و فاصلهٔ انتخابشده اندازهگیری کنید. اگر کاراکترها ۱۰×۲۰ پیکسل باشند، فیلترهای اندازهٔ Blob را بهگونهای تنظیم کنید که هر چیزی کمتر از ۸×۱۶ یا بیشتر از ۱۵×۳۰ را فیلتر کند تا تغییرات جزئی را نیز در برگیرد.
-
-
تحمل زاویهٔ چرخش (Skew) و چرخش
-
اگر سینی ممکن است کمی چرخیده باشد (مثلاً ±۵°)، اجازه دهید موتور OCR چنین زاویهای را تحمل کند و پارامتر “Max skew angle” را روی ۱۰° تنظیم کنید.
-
به جای اعتماد کامل به تحمل چرخش، میتوان قبل از OCR بلوکی برای «پاکسازی چرخش» (Deskew) اضافه کرد که چرخش جزئی را اصلاح میکند (با استفاده از تبدیل خطی یا تصحیح زاویه روی اساس روش هاف (Hough)).
-
-
پارامترهای افزایش کنتراست
-
برای بوردهای با کنتراست بسیار کم، از عملیات ریختشناختی (Morphological) مانند فیلتر “Top-Hat” یا “Bottom-Hat” استفاده کنید تا برجستگی کاراکترها برجستهتر شود. تبدیل Top-Hat، بهطور مثال، تصویر بازشده (Opened) را از تصویر اصلی کم میکند و ویژگیهای روشن روی پسزمینهٔ تاریک را تأکید میکند.
-
از آستانهگذاری تطبیقی (Adaptive Thresholding) بهجای آستانهٔ سراسری (Global Threshold) استفاده کنید. روشهای تطبیقی آستانه برای هر بخش تصویر یک آستانه محلی محاسبه میکنند و تغییرات نور موضعی را در نظر میگیرند.
-
-
حذف نویز
-
کارخانهها معمولاً نویز نمکی (Salt-and-Pepper Noise)—ذرات گردوغبار، پاشش روغن یا نقاط داغ حسگر—تولید میکنند. یک فیلتر میانگینگیر کوچک (مثلاً ۳×۳ یا ۵×۵) برای حذف نویز نمکی بدون تار کردن لبههای تیز کاراکترها کافی است.
-
-
ارزیابی وامداری (Confidence Scoring)
-
قابلیت خروجی نمرهٔ اطمینان (Confidence Score) برای هر کاراکتر یا کل رشته را در موتور OCR فعال کنید. اگر نمرهٔ اطمینان پایینتر از آستانهٔ تعریفشده (مثلاً ۸۵٪) باشد، سینی برای اسکن مجدد یا مداخلهٔ دستی ارسال شود تا از ورود دادههای نامعتبر به سیستمهای پاییندستی جلوگیری شود.
-
-
روشی برای بازگشت ذخیره (Fallback)
-
برای بوردهای حیاتی، میتوان از دو دوربین با زاویههای مختلف (مثلاً جلو و کنار) استفاده کرد و نتایج OCR را مقایسه کرد. اگر یک دوربین خواندن را نتوانست انجام دهد، دوربین دیگر ممکن است موفق شود. این افزونگی میتواند نرخ خواندن را از ۹۹.۹٪ به نزدیک ۱۰۰٪ برساند، البته هزینهٔ سختافزار و یکپارچهسازی را افزایش میدهد.
-
۴. یکپارچهسازی در سیستمهای موجود
بعد از آنکه OCR با موفقیت کد سینی را خواند، باید آن را در اکوسیستم IT/OT کارخانه یکپارچه کنید:
-
ضبط داده و تحلیل
-
هر کد شناساییشده را به همراه زمانسنجی (Timestamp)، شناسهٔ خط تولید و نمرهٔ اطمینان در یک پایگاه داده یا تاریخیاب (Data Historian) ذخیره کنید. این اطلاعات بعداً برای تحلیل بهرهوری، گزارشات رهگیری و شناسایی گلوگاهها (Bottlenecks) استفاده میشود.
-
از این دادهها برای ایجاد داشبوردهای تصویری استفاده کنید—نرخ خواندن در طول زمان، نرخ خطا در هر شیفت یا تفاوت عملکرد بین سبکهای مختلف سینی.
-
-
ارتباط با PLC/کنترلرها
-
از یک خط I/O دیجیتال یا فیلدباس صنعتی برای ارسال سیگنال «OCR موفق» یا «OCR ناموفق» به PLC استفاده کنید. PLC میتواند تصمیم بگیرد که سینی را در مسیر عادی هدایت کند، به ایستگاه بازرسی بفرستد یا خط را متوقف کند.
-
برای یکپارچهسازی پیچیدهتر، از پروتکلهای اترنت صنعتی (EtherNet/IP، PROFINET، Modbus TCP) جهت ارسال کد شناسایی شده بهعنوان رشتهٔ ASCII به PLC استفاده کنید. این امکان را میدهد تا تصمیمات بلادرنگ (مثل انتخاب برنامهٔ تست بر اساس شناسهٔ سینی) گرفته شود.
-
-
اتصال به MES
-
به جای ذخیرهٔ محلی داده، سیستم OCR را مستقیماً به MES از طریق سرور OPC UA متصل کنید. به محض خواندن یک کد، MES وضعیت دسته (Lot) را (مثلاً «برش ویفر انجام شد»، «تست انجام شد»، «بستهبندی شد») بهروزرسانی میکند و مراحل بعدی را مطلع میسازد.
-
این یکپارچهسازی بلادرنگ باعث میشود اگر یک فرآیند پایین دستی (مثلاً تست نهایی) نقصی پیدا کند، MES دقیقاً بداند کدام دسته ویفر و ایستگاه تست منشأ مشکل بوده است و تحلیل ریشهای (Root Cause Analysis) سریعتر انجام شود.
-
-
رابطهای کاربری برای اپراتورها
-
یک رابط کاربری لمسی (Touchscreen HMI) در ایستگاه بازرسی یا مسیر دورریز (Reject Lane) مستقر کنید. اگر OCR شکست خورد، اپراتور بتواند دستی کد سینی را وارد کند. سیستم میتواند تصویر نمونه از حالتهای رایج خطا (مثل «سینی نامرتب»، «کاراکتر لکهدار») را نمایش دهد تا اپراتور در عیبیابی کمک بگیرد.
-
حالت «آموزش» (Teach Mode) فراهم کنید تا اپراتورها بتوانند نمونههای جدید از سبکهای سینی (مثلاً وقتی سینی جدیدی معرفی میشود) را ثبت کنند و به سرعت مدل OCR را مجدداً آموزش دهند یا پارامترها را تنظیم کنند.
-
OCR مبتنی بر هوش مصنوعی برای کاربردهای پیچیده
در حالی که pylon vTool OCR بسیاری از کاربردهای استاندارد را پوشش میدهد، در برخی موارد کاراکترها در چند موقعیت مختلف قرار دارند، فونتها ممکن است نامنظم باشند یا پسزمینه بسیار شلوغ باشد. در این شرایط، راهکار OCR مبتنی بر هوش مصنوعی—که از مدلهای یادگیری عمیق استفاده میکند—دقت و مقاومت بهمراتب بالاتری ارائه میدهد. در ادامه بررسی میکنیم که چه زمانی و چگونه باید هوش مصنوعی را در جریان OCR ادغام نمود.
۱. چه زمانی از OCR هوش مصنوعی استفاده کنیم
-
مثابت نبودن موقعیت متن: اگر کدهای سینی میتوانند در موقعیتهای مختلفی روی سینی ظاهر شوند (مثلاً لبه بالایی، لبه پایینی، یا جداره کناری)، یک مدل مبتنی بر هوش مصنوعی میتواند ابتدا همهٔ ناحیههای متنی ممکن را شناسایی کند، بدون نیاز به دانستن موقعیت دقیق.
-
کاراکترهای تحریفشده یا منحنی: در برخی سینیها، کاراکترها ممکن است روی لبهای منحنی قالبزده شده باشند یا روی سطح نسبتاً خمشده چاپ شده باشند. در این شرایط، OCR مبتنی بر تطبیق الگو (Template Matching) مشکلساز است، اما مدلهای یادگیری عمیق که روی دادههای فراوانی از متنهای تحریفشده آموزش دیدهاند، قادر به تطبیق هستند.
-
فونتهای سفارشی یا زبانهای مختلط: اگر سینیها از فونت اختصاصی استفاده کنند یا نمادهای ویژهای داشته باشند، مدلهای هوش مصنوعی که روی مجموعه دادهٔ خاص کارخانه آموزش دیدهاند میتوانند بدون تنظیم دستی جزئیات، آنها را شناسایی کنند.
-
پسزمینههای پیچیده: در صحنههای شلوغ—جایی که قطعات جانبی و تجهیزات یا بوردهای دیگر ممکن است چندلایه در پسزمینه دیده شوند—نیاز به جداسازی ناحیهٔ متن از نویز پسزمینه است. شبکههای عصبی برای این کار (مانند U-Net یا Mask R-CNN) توانایی بالایی دارند.
۲. مدیریت موقعیتهای متغیر و کاراکترهای تحریفشده
در یک جریان کاری OCR مبتنی بر هوش مصنوعی، معمولاً دو مرحله اصلی وجود دارد: تشخیص متن (Text Detection) و شناسایی کاراکتر (Text Recognition).
-
تشخیص متن (Localization Stage)
-
شبکههای R-CNN مبتنی بر ناحیه (Region-Based CNN): مدلهایی مانند Faster R-CNN میتوانند مستطیلهای اطراف ناحیههای متنی را شناسایی کنند. با آموزش مدل روی تصاویر حاوی جعبههای محصورکننده (Bounding Box) دور کد سینی، شبکه یاد میگیرد تا مکانهای متنی را بدون توجه به جهت و چرخش شناسایی کند.
-
یکبار اجرا (Single-Shot) یا YOLO (You Only Look Once): این مدلهای سریع تشخیص اشیا را میتوان برای یافتن موقعیت متن در زمان واقعی (Real-Time) آموزش داد—اغلب کمتر از ۵۰ میلیثانیه برای هر تصویر—که برای خطوط تولید با سرعت بالا مناسب است.
-
-
شناسایی متن (OCR Stage)
-
پس از اینکه ناحیهٔ متنی پیشبینیشده مشخص شد، تصویر برشخورده از آن ناحیه به شبکهٔ شناسایی متن (مانند CRNN—Convolutional Recurrent Neural Network) ارسال میشود.
-
CRNN معمولاً شامل لایههای CNN برای استخراج ویژگی تصویری و لایههای RNN برای مدلسازی توالی کاراکترها است و در پایان، خروجی متنی (رشتهٔ شناساییشده) تولید میشود.
-
این مدلها اغلب از تابع هزینه CTC (Connectionist Temporal Classification) در زمان آموزش استفاده میکنند که به آنها امکان میدهد طول توالیهای متغیر (مثلاً برخی کدها ۵ کاراکتر، برخی ۶) را پردازش کنند.
-
-
افزایش داده برای مقاومت بالا
-
در زمان آموزش، از تکنیکهای متفاوتی مانند چرخش (±۱۵°)، تغییر مقیاس (۹۰–۱۱۰٪)، تاری (Gaussian Blur با سیگما تا ۲) و تنظیم روشنایی/کنتراست برای شبیهسازی شرایط نوری و فوکوس متغیر استفاده کنید.
-
مدل را روی «نمونههای سخت» مانند پسزمینههای صنعتی، لکههای روغن، گردوغبار و موضعیهای پوشاندهشده آموزش دهید تا یاد بگیرد شکلهای بیاهمیت را نادیده بگیرد و بر کاراکترهای واقعی تمرکز کند.
-
-
استنتاج و آستانهگذاری اطمینان (Confidence Thresholding)
-
در زمان اجرا (Runtime)، مدل برای هر کاراکتر و کل رشتهٔ شناساییشده یک نمرهٔ اعتماد (Confidence) خروجی میدهد. یک آستانهٔ مناسب (مثلاً ۰.۹۰) تعیین کنید تا خواندههای با اعتماد پایین را رد کنید.
-
یک مکانیزم بازگشتی (Fallback) به OCR سنتی (pylon vTool OCR) پیاده کنید تا اگر اعتماد مدل هوش مصنوعی بین یک محدودهٔ پایینتر (مثلاً ۰.۷۰–۰.۹۰) بود، از OCR سریعتر سنتی برای خواندن استفاده شود. این روش ترکیبی تضمین میکند که خواندنهای آسان با الگوریتم سریعتر انجام شود و موارد دشوارتر به مدل هوش مصنوعی ارجاع داده شود.
-
۳. پسزمینههای شلوغ و تغییرات دنیای واقعی
خطوط تولید واقعی در کارخانهها به ندرت شرایطی ایدهآل ارائه میدهند؛ در عوض، ممکن است با موارد زیر مواجه باشید:
-
بوردهای دیگر در پسزمینه
-
نقاله یا غلتکهایی که وارد فریم میشوند
-
کابلها، شیلنگها یا تجهیزات دیگر که بخشی از لبهٔ سینی را میپوشانند
-
ماتی حرکت (Motion Blur) اگر سینی با سرعت زیاد جابجا شود
-
لکههای روغن یا آلودگیهای سطحی روی سینی
یک راهکار OCR مبتنی بر هوش مصنوعی میتواند برای مقابله با این دشواریها آموزش ببیند:
-
شبکههای تقسیمبندی معنایی (Semantic Segmentation Networks)
-
معماریهایی مانند U-Net یا SegNet میتوانند یک ماسک پیکسلی (Pixel-wise) از ناحیههای متن تولید کنند. برخلاف جعبههای محصورکننده (Bounding Boxes)، ماسکهای تقسیمبندی دقیقاً مرز شکل کاراکترها را مشخص میکنند و دقت شناسایی را بالاتر میبرند.
-
-
تقسیمبندی نمونهای (Instance Segmentation)
-
برای بوردهایی که دارای چندین کد هستند (مثلاً یک شماره سریال در لبه بالا و تاریخ تولید در جداره کناری)، تقسیمبندی نمونهای (مانند Mask R-CNN) میتواند هر نمونهٔ متنی را جدا کند و به سیستم اجازه میدهد هر کد را به برنامهٔ پاییندستی متفاوتی ارسال کند (مثلاً رهگیری در مقابل تضمین کیفیت).
-
-
تطبیق دامنه و یادگیری آنلاین (Domain Adaptation و Online Learning)
-
اغلب کارخانهها دورهای بوردهای جدید معرفی میکنند یا بوردهای موجود را تغییر میدهند. با استفاده از یک چارچوب یادگیری آنلاین (مثلاً تنظیم تدریجی مدل)، مدل AI میتواند بدون آموزش مجدد کامل خود را با ظاهر جدید سینی تطبیق دهد. اپراتورها کافی است چندین تصویر جدید ضبط و با جعبههای محصورکننده و متن برچسبگذاری کنند و یادگیری افزایشی (Incremental Learning) را برای بهروزرسانی وزنهای مدل اجرا کنند.
-
-
ملاحظات استقرار در لبه (Edge Deployment)
-
اجرای مدلهای هوش مصنوعی در زمان واقعی در لبه خط تولید نیازمند انتخاب سختافزار مناسب—مثلاً یک کامپیوتر صنعتی مجهز به GPU (مانند NVIDIA Jetson یا کارت RTX) یا شتابدهندههای استنتاج مخصوص مثل Intel® Movidius™ Myriad™ X یا Google Coral TPU.
-
از چارچوبهای بهینهسازی مانند TensorRT یا OpenVINO™ بهره ببرید تا اجرای مدل (Inference) سریعتر و با تأخیر کمتر شود.
-
OCR مبتنی بر هوش مصنوعی بوردهای چیپ/آیسی با pylon vTools: دستورالعمل و نتایج
برای ملموستر کردن مفاهیم مطرحشده، در این بخش یک مثال عملی از پیادهسازی OCR بوردهای چیپ با استفاده از pylon vTools را بررسی میکنیم؛ از ایجاد دستورالعمل (Recipe) تا اندازهگیری عملکرد.
۱. گردش کار مرحله به مرحله
-
ارزیابی اولیه و جمعآوری نمونهها
-
مجموعهای متنوع از بوردهای چیپ را از خط تولید جمعآوری کنید: رنگهای مختلف سینی (خاکستری روشن، خاکستری تیره، سیاه)، اتمام سطحهای مختلف (مات، نیمهبراق)، سبکهای کاراکتر (برجسته، حک لیزری) و سطوح مختلف سایش.
-
تصاویر نمونه را تحت شرایط نوری تولید واقعی و همچنین با نور پیشنهادی بهینه (نور حلقهای میدان تاریک با پلاریزه) بگیرید. مطمئن شوید که نمونهها شامل بوردهایی در لبههای مختلف نقاله—چه کمی خارج کانون (فوکوس) و چه نیمه در سایه—باشند.
-

-
تنظیم سختافزار
-
دوربین: Basler ace سری با حسگر شاتر جهانی ۵ مگاپیکسلی. اتصال Micro USB3 به کامپیوتر پردازش pylon.
-
لنز: لنز ماکرو ۱۶ میلیمتری با فوکوس موتورایز.
-
نورپردازی: نور حلقهای LED با زاویه کم (۱۵°) برای ایجاد اثر میدان تاریک. فیلتر پلاریزه روی حلقه نور و لنز نصب شده است.
-
تحریک: یک سنسور نوری (Optical Sensor) درست قبل از رسیدن سینی به میدان دید دوربین قرار گرفته و پالس تحریک را برای اکتساب تصویر و استروب LED ارسال میکند.
-
-
ایجاد دستورالعمل در pylon vTool
-
تعریف ROI: با استفاده از نمای زنده (Live View) در pylon Viewer، یک مستطیل پیرامون ناحیهٔ کد سینی رسم کنید. اندازهٔ ROI در رزولوشنی که انتخاب شده، تقریباً ۱۵۰×۵۰ پیکسل است و به صورت افقی وسط قابی قرار دارد.
-
پیشپردازش:
-
تبدیل به خاکستری (Grayscale).
-
فیلتر میانگینگیر ۵×۵ (Median Filter).
-
افزایش کنتراست با برابرسازی هیستوگرام تطبیقی (Clip Limit = 2.0، Tile Grid Size = 8×8).
-
آستانهگذاری تطبیقی (Adaptive Thresholding) با اندازه بلوک ۱۵ و مقدار C برابر ۵.
-
-
جداسازی Blob:
-
حداقل اندازه Blob: ۸۰ پیکسل.
-
حداکثر اندازه Blob: ۶۰۰ پیکسل.
-
محدوده نسبت ابعاد (Aspect Ratio): ۰.۳ تا ۱.۰ (برای شامل کردن حروف کشیده مانند “I” و ارقام پهن مانند “0”).
-
-
موتور OCR مبتنی بر هوش مصنوعی:
-
مجموعه کاراکتر: A–Z، 0–9.
-
طول رشتهٔ مورد انتظار: ۵ کاراکتر.
-
حداکثر زاویه انحراف (Skew): ۱۰°.
-
محدوده ارتفاع کاراکتر: ۱۲–۲۵ پیکسل.
-
-
اعتبارسنجی (Validation): عبارت باقاعده (Regular Expression) “[A-Z][0-9]{4}”. هر خواندهای که با این الگو مطابقت نداشته باشد، مجدداً اسکن میشود.
-
خروجی: کد شناختهشده از طریق TCP/IP به MES ارسال میشود. یک خط I/O دیجیتال در صورت خواندن موفقیتآمیز HIGH میشود؛ در غیر این صورت، خط خطا پالس میزند.
-
-
آزمایش آفلاین و تکرار تنظیمات
-
دستورالعمل را روی ۱,۰۰۰ تصویر نمونه اجرا کنید. نرخ خواندن اولیه ۹۸.۵٪ است—که قابل قبول نیست.
-
موارد شکست را بررسی کنید: اکثر خطاها وقتی رخ میدهند که سطح سینی با روغن یا خراشهای جزئی پوشیده شده باشد. در این حالت، کاراکترها بهصورت لکهدار در تصویر ظاهر میشوند.
-
پیشپردازش را تنظیم کنید:
-
افزودن تبدیل مورفولوژیک «Top-Hat» (هسته مورفولوژیک ۱۵×۱۵) قبل از آستانهگذاری تطبیقی تا برجستگی کاراکتر واضحتر شود.
-
افزایش پارامترهای افزایش کنتراست (Clip Limit از 2.0 به 3.0).
-
گسترش محدوده نسبت ابعاد Blob به ۰.۲–۱.۲ برای شامل کردن کاراکترهای کمی تحریفشده.
-
-
دوباره روی ۱,۰۰۰ تصویر اجرا کنید: نرخ خواندن به ۹۹.۷٪ بهبود مییابد. باقیماندهٔ خطاها عمدتاً مربوط به بوردهایی است که در لبههای نقاله قرار دارند (کمی خارج از ROI).
-
ROI را ۱۰ پیکسل در هر طرف بزرگتر کنید و آستانهٔ اعتماد را به ۸۰٪ کاهش دهید. نرخ خواندن نهایی: ۹۹.۹۲٪.
-
-
استقرار آنلاین
-
مجموعهٔ دوربین و نورپردازی را به خط تولید انتقال دهید. تجهیزات دوربین و سنسورهای تحریک را به نقاله متصل کنید.
-
کامپیوتر پردازش pylon را از طریق اترنت به MES متصل کنید و ارتباط OPC UA را پیکربندی کنید.
-
نظارت بلادرنگ (Real-Time): دستورالعمل را در «حالت زنده» اجرا و کدهای شناساییشده را در HMI برای بازبینی اپراتور پخش کنید. در طول اولین شیفت ۸ ساعته، OCR پنجهزار سینی را پردازش میکند و فقط ۳ خواندن ناموفق (نرخ خطای ۰.۰۶٪) رخ میدهد. هر شکست ثبت میشود تا توسط اپراتور بازبینی شود.
-
اپراتورها تأیید میکنند که دو مورد از سه شکست ناشی از کج بودن بیشازحد سینی خارج از میدان دید دوربین بوده—که مشکل اپراتور تلقی میشود. شکست سوم مربوط به سینیای بود که روغن زیادی داشت؛ پس از تمیزکاری، مجدداً با موفقیت خوانده شد.
-
۲. نمونه نتایج و معیارهای عملکرد
جدول انتهای مقاله
تحلیل نتایج:
-
فاز آزمایش آفلاین برای تنظیم دقیق جریان پیشپردازش و پارامترهای جداسازی Blob اهمیت زیادی داشت.
-
در انتقال به استقرار آنلاین، متغیرهای واقعی—مانند کج بودن گاهبهگاه سینی و آلودگی روغنی—مورد آزمایش قرار گرفت. با این حال، نورپردازی مناسب و دستورالعمل تنظیمشده توانست به نرخ خواندن آفلاین نزدیک شود.
-
زمان متوسط پردازش ۵۰ میلیثانیه برای هر سینی فاصلهٔ زیادی تا تبدیل شدن به گلوگاه تولید (۱۹–۲۰ سینی در ثانیه) دارد.
-
مداخلهٔ اپراتوری بسیار کم (تنها سه سینی از ۵,۰۰۰) صرفهجویی قابلتوجهی در نیروی کار ایجاد و ریسک توقف تولید را به حداقل رساند.
مزایای یک راهکار OCR مبتنی بر هوش مصنوعی جامع برای بوردهای چیپ
سرمایهگذاری در یک سیستم OCR قابل اعتماد برای بوردهای چیپ و آیسی مزایای متعددی در ابعاد عملیاتی، کیفی و مالی دارد:
-
افزایش قابلیت رهگیری (Traceability)
-
ردیابی سطح دسته (Lot-Level Tracking): شناسهٔ منحصربهفرد هر سینی با دقت خوانده شده و ثبت میشود. اگر نقصی در مراحل بعدی (مثلاً در تست نهایی) رخ دهد، سابقهٔ کامل تولید—از دسته ویفر تا ایستگاه تست و اپراتور—قابل بازسازی است.
-
پاسخگویی به الزامات قانونی: در برخی صنایع (مانند خودروسازی یا تجهیزات پزشکی)، استانداردهای نظارتی (ISO 26262، ISO 13485) نیازمند ردیابی دقیق هستند. OCR خودکار، تطابق با این استانداردها را بدون نیاز به مستندسازی دستی فراهم میکند.
-
-
کاهش خطای انسانی
-
حذف ورود دستی داده: اپراتورها نیازی به خواندن بصری کدها و وارد کردن دستی آنها ندارند. حتی یک خطای تایپی میتواند سینی را به مسیر اشتباهی بفرستد و منجر به ضایعات یا بازکاری (Rework) شود.
-
نرخ خواندن مداوم و ثابت: سیستم بینایی ماشینی خسته نمیشود و خطاهای تکراری ناشی از خستگی اپراتور را ندارد. حتی پس از چند شیفت، عملکرد آن ثابت میماند.
-
-
افزایش ظرفیت و بهرهوری
-
زمان چرخهٔ سریعتر: خواندن خودکار OCR کمتر از ۵۰ میلیثانیه طول میکشد، در حالی که خواندن دستی و ورود اطلاعات ممکن است ۲–۳ ثانیه طول بکشد. در تعداد بالای سینیها، این صرفهجویی زمانی بسیار قابلتوجه است.
-
کاهش توقفهای غیرضروری: دقت بالای خواندن باعث میشود آلارمهای کاذب و نیاز به بازرسی دستی کاهش یابد. این به جریان روانتر تولید و افزایش OEE کمک میکند.
-
-
صرفهجویی در هزینه
-
کاهش ضایعات و بازکاری: خواندن دقیق سینی از مخلوط شدن دستهها و ضایعات پرهزینه جلوگیری میکند.
-
صرفهجویی در نیروی کار: نیاز به مداخلهٔ دستی بسیار کاهش مییابد و اپراتورها میتوانند روی وظایف با ارزشتر تمرکز کنند (مانند نگهداری دستگاهها و بهبود فرایند).
-
نگهداری کمتر و توقف کمتر: سیستمهای بینایی حرفهای معمولاً نیاز به نگهداری کمی دارند. قابهای محافظ، نور و دوربینهای صنعتی غالباً تنها به پاکسازی سطح لنز و بهروزرسانی نرمافزاری دورهای نیاز دارند.
-
-
مقیاسپذیری و آیندهپذیری (Future-Proofing)
-
سازگاری آسان با طراحیهای جدید سینی: با رویکرد مبتنی بر دستورالعمل (Recipe) در pylon، افزودن پشتیبانی برای سینی یا فونت جدید به پارامترهای جدید بسنده میکند. مدلهای مبتنی بر هوش مصنوعی نیز با چند نمونه تصویر جدید قابل بهروزرسانی هستند.
-
معماری ماژولار: کنترلکنندههای بینایی، سیستمهای نورپردازی و ماژولهای OCR را میتوان در چندین خط یا سایت تولیدی تکثیر کرد. دستورالعملهای استاندارد شده میتوانند در کل سازمان پیاده شوند و یکنواختی را تضمین کنند.
-
ادغام با ابتکارات صنعت ۴.۰ (Industry 4.0): جریان یکپارچهٔ دادهها به MES، پایگاههای دادهٔ تاریخی و پلتفرمهای تحلیلی باعث ایجاد داشبوردهای کارخانه هوشمند، پیشبینی نگهداری و برنامههای بهبود مستمر میشود.
-
بهترین شیوهها و نکات پیادهسازی
با بهرهگیری از تجربیات متعدد در پیادهسازیهای OCR، در ادامه توصیههایی عملی برای اطمینان از موفقیت ارائه شده است:
-
ابتدا تصویرهای باکیفیت تهیه کنید
-
روی طراحی نورپردازی و بهینهسازی فوکوس تمرکز کنید. اگر در تصاویر آزمایشی اولیه کاراکترها همچنان کمکنتراست یا تار هستند، هیچ تعداد تنظیمات نرمافزاری نمیتواند این مشکل را بهصورت کامل جبران کند.
-
برای کاراکترهای برجسته از نور حوزه تار (Darkfield) با پخشکننده (Diffuser) و فیلتر پلاریزه استفاده کنید.
-
-
در صورت نیاز از رویکرد ترکیبی (Hybrid) استفاده کنید
-
از pylon vTool OCR برای خواندنهای ساده و با کنتراست بالا استفاده کنید و موارد دشوار را به مدل OCR مبتنی بر هوش مصنوعی ارجاع دهید. این دو سطحی کردن جریان کاری هم سرعت و هم مقاومت را تضمین میکند.
-
مکانیزم مسیریابی مبتنی بر اعتماد (Confidence-Based Routing) پیاده کنید: خواندههای با اطمینان بالا (> ۹۰٪) پذیرفته شوند؛ خواندههای با اعتماد ۷۰–۹۰٪ به مدل AI ارجاع داده شوند؛ خواندههای با اعتماد < ۷۰٪ به اسکن مجدد یا مداخلهٔ دستی بروند.
-
-
اعتبارسنجی معنیدار را پیاده کنید
-
از قواعد کسبوکار (مثلاً الگوی فرمت کد، طرح شمارهگذاری دسته، رقم کنترلی) برای اعتبارسنجی خروجیهای OCR استفاده کنید. خواندههای ناسازگار را رد کنید تا دادهٔ اشتباه وارد سیستمهای بعدی نشود.
-
از افزونگی استفاده کنید: چند فریم از هر سینی در طول عبور از زیر دوربین ثبت کنید؛ مطمئن شوید دو خواندن پیاپی مطابقت دارند قبل از ثبت کد در MES.
-
-
مشارکت اپراتورها و نگهداری بهعهدهٔ مالک تجهیزات
-
اپراتورها را در شناسایی حالتهای رایج خطا (مثلاً روغن زیاد، سینی کج، مانع روی لنز) آموزش دهید. کیتهای سادهٔ تمیزکاری (دستمال مخصوص لنز، الکل) و راهنمای سریع (Quick Reference) در اختیارشان قرار دهید.
-
بازرسیهای دورهای خط را برنامهریزی کنید—آمار نرخ خواندن، دلایل خطا و اقدامات نگهداری را ثبت و بررسی کنید. از این دادهها برای بهبود دستورالعملهای OCR و تنظیم نور استفاده کنید.
-
-
برای چرخهٔ عمر سینیها برنامهریزی کنید
-
هر از چندگاهی طراحی سینی جدید معرفی یا بوردهای موجود تغییر میکنند. یک چرخهٔ بهبود مستمر تدوین کنید: هرگاه سینی جدیدی آمد، ۵۰–۱۰۰ تصویر نمونه از آن در شرایط تولیدی بگیرید، دستورالعمل OCR را تنظیم کنید و نرخ خواندن را قبل از استقرار کامل اعتبارسنجی نمایید.
-
یک بانک اطلاعاتی «مدیریت سینی» بسازید که در آن پارامترهای هندسی هر سبک سینی، مشخصات فونت کد، تنظیمات نور پیشنهادی و … ثبت شود تا هنگام تغییر سبک سینی، تنظیمات سریعتر انجام گیرد.
-
-
مستندسازی و خودکارسازی روشهای کالیبراسیون
-
دستورالعملهای عملیاتی استاندارد (SOP) برای کالیبرهکردن فوکوس، شدت نور و پارامترهای نوردهی تدوین و منتشر کنید. جایی که ممکن است، خودکارسازی کنید: مثلاً اسکریپتی برای تنظیم پارامترهای دوربین از طریق API pylon بنویسید یا یک ویزارد کالیبراسیون در HMI تعبیه کنید که اپراتورها را در هر مرحله راهنمایی کند.
-
دورهای پارامترهای کالیبراسیون دوربین را بررسی و ثبت کنید تا انحراف احتمالی (مثلاً کالیبراسیون موتور فوکوس پس از چند سال استفاده) مشخص شود.
-
-
از تحلیل داده برای بهبود مستمر استفاده کنید
-
از دادههایی که توسط سیستم OCR ثبت میشود—زمانسنجی، شناسهٔ خط، نمرهٔ اعتماد، دلیل شکست—برای شناسایی الگوها استفاده کنید. بهعنوان مثال، اگر نرخ شکست در یک شیفت خاص افزایش یافته، ممکن است نشاندهندهٔ اشکال در نورپردازی یا بیدقتی اپراتور باشد.
-
روندها را مصورسازی کنید: اگر یک دستهٔ خاص از سینیها مکرراً نرخ خواندن پایینی داشته باشد، احتمالاً نقص در تولید آن دسته سینی وجود دارد که باید اصلاح شود.
-
نتیجهگیری و دعوت به اقدام
شناسایی نوری کاراکتر (OCR مبتنی بر هوش مصنوعی) کارآمد روی بوردهای چیپ و آیسی فراتر از یک ویژگی اختیاری است؛ یک مؤلفهٔ ضروری برای تولید مدرن نیمههادی است. با خودکارسازی خواندن شناسههای سینی، تولیدکنندگان میتوانند خطای انسانی را حذف، سرعت تولید را افزایش، ردگیری کامل را تضمین و از الزامات نظارتی پیروی کنند. اما دستیابی به دقت بالا (> ۹۹.۹٪) در این زمینه نیازمند نگرش جامع است: بهینهسازی اکتساب تصویر (نورپردازی و فوکوس)، استفاده از یک موتور OCR قدرتمند مثل pylon vTool OCR و در صورت لزوم، ادغام OCR مبتنی بر هوش مصنوعی برای چالشهای سختتر.
خلاصهٔ موارد کلیدی:
-
درک چالش: کاراکترهای برجسته با کنتراست پایین در شرایط نوری و فوکوس نامناسب میتوانند سیستمهای OCR سنتی را ناکارآمد کنند.
-
سرمایهگذاری در سختافزار: دوربین، لنز، نورپردازی و فوکوس خودکار مناسب را انتخاب کنید تا تصاویر با کیفیت بالا تولید شود.
-
استفاده از pylon vTools: از قابلیت کشیدن و رها کردن (Drag-and-Drop) دستورالعملسازی، پیشپردازشهای بهینه و عملکرد با سرعت بالا بهره ببرید. دستورالعمل را تکرار کنید تا نرخ خواندن به بالای ۹۹.۹٪ برسد.
-
توسعه با هوش مصنوعی در صورت نیاز: برای موقعیتهای متغیر یا پسزمینههای شلوغ، از مدلهای هوش مصنوعی بهره ببرید که با تصاویر واقعی سینی آموزش دیدهاند.
-
یکپارچهسازی و اعتبارسنجی: سیستم را به PLC، MES و HMI اپراتورها متصل کنید. برای تضمین صحت داده از قواعد اعتبارسنجی و خواندن اضافی (Redundant Reads) استفاده کنید.
-
بهکارگیری بهترین شیوهها: روشهای کالیبراسیون را مستندسازی کنید، اپراتورها را آموزش دهید و با استفاده از داشبوردهای تحلیلی عملکرد را بهبود دهید. بهروزرسانی دستورالعمل OCR را در صورت معرفی سبک جدید سینی یا تغییرات فرآیند در دستور کار قرار دهید.
آمادهاید تا موفقیت OCR مبتنی بر هوش مصنوعی را روی بوردهای چیپ خود تجربه کنید؟ تیم متخصص ما آماده است تا در هر مرحله همراه شما باشد: از مطالعات امکانسنجی اولیه و مشاوره نورپردازی تا توسعه دستورالعمل و یکپارچهسازی در محل. اجازه ندهید کاراکترهای کمکنتراست و فاصلههای متغیر باعث تأخیر در خط تولید شود—همین امروز با ما تماس بگیرید تا در مورد نحوهٔ ارائهٔ دقت و اطمینان مورد نیاز شما توسط pylon vTools و راهکارهای OCR مبتنی بر هوش مصنوعی شرکت Basler صحبت کنیم.
همین حالا برای پروژه OCR مبتنی بر هوش مصنوعی خود از ما کمک بگیرید!
-
زمانبندی تماس مشاوره: مسائل خاص خود را با متخصصان بینایی ماشین ما در میان بگذارید.
-
درخواست کیت آزمایشی (Trial Kit): دوربین، نور و نرمافزار pylon را در محیط خود آزمایش کنید.
-
دریافت دستورالعملهای نمونه: با استفاده از قالبهای دستورالعمل آزمایششده، توسعه را تسریع کنید.
-
دریافت مستندات فنی: مقالات سفید (Whitepaper)، یادداشتهای کاربردی (Application Notes) و راهنماهای بهترین شیوه را بررسی کنید.
فرآیند شناسایی بوردهای چیپ و آیسی را از مانعی برای تولید به یک فرایند کاملاً خودکار و یکپارچه تبدیل کنید—زیرا در تولید نیمههادی، هر ثانیه اهمیت دارد و هر چیپ ارزشمند است.
| معیار | آزمایش آفلاین | استقرار آنلاین (اولین ۸ ساعت) |
|---|---|---|
| تعداد تصاویر/بوردهای نمونه | ۱,۰۰۰ | ۵,۰۰۰ |
| نرخ خواندن اولیه (قبل از تنظیم) | ۹۸.۵٪ | ندارد |
| نرخ خواندن نهایی (پس از تنظیم) | ۹۹.۹۲٪ | ۹۹.۹۴٪ |
| زمان پردازش OCR به ازای هر سینی (میلیثانیه) | ۴۵ ms | ۵۰ ms |
| تعداد دوربینهای در حال کار | ۱ | ۱ |
| پیکربندی نورپردازی | LED حلقهای میدان تاریک | LED حلقهای میدان تاریک |
| تعداد شکستهای خواندن | ۱ (از ۱۲۹۲ تلاش مجدد) | ۳ |
| میانگین زمان برای پردازش مجدد سینی ناموفق | ۳.۲ ثانیه | ۴.۰ ثانیه |





